
OCP MX Scaling Formats
Comeback of (somewhat) block floating-point

In this post we review key elements of the specification of the Open Compute Project MX Scaling format standard. We also briefly review what support exists for it today in hardware and in particular the on-going RISC-V extension projects to support OFP8 and OFP4.
Neural networks have become ubiquitous and they have shown a very good resistance to numerical errors and a large affinity for computation with limited precision. This is in particular true for the storage of weigths/parameters (Quantized Neural Networks). This has triggered interest for smaller and smaller numerical formats. BFloat16 is often cited as one of the key success factor for the Google TPU architecture: finding the right balance between range (exponent size) and relative accuracy (mantissa size) is key to NN performance. It seems neural network can make use of even smaller precisions (often by factoring a scaling factor and a bias across a subset of the tensor dimensions).
The Open Compute Project (OCP) has been active to define and standardize the use of such small formats. It published a standard for 8-bit floating-point formats (OFP8) that we covered in a previous post (in particular comparing them with the state of the IEEE P3109 binary8 proposal)":
Partial Taxonomy of 8-bit Floating-Point Formats

This blog post is not centered on RISC-V, it reviews recent developments in Floating-Point arithmetic around the standardization of small (8-bit) floating-point formats.
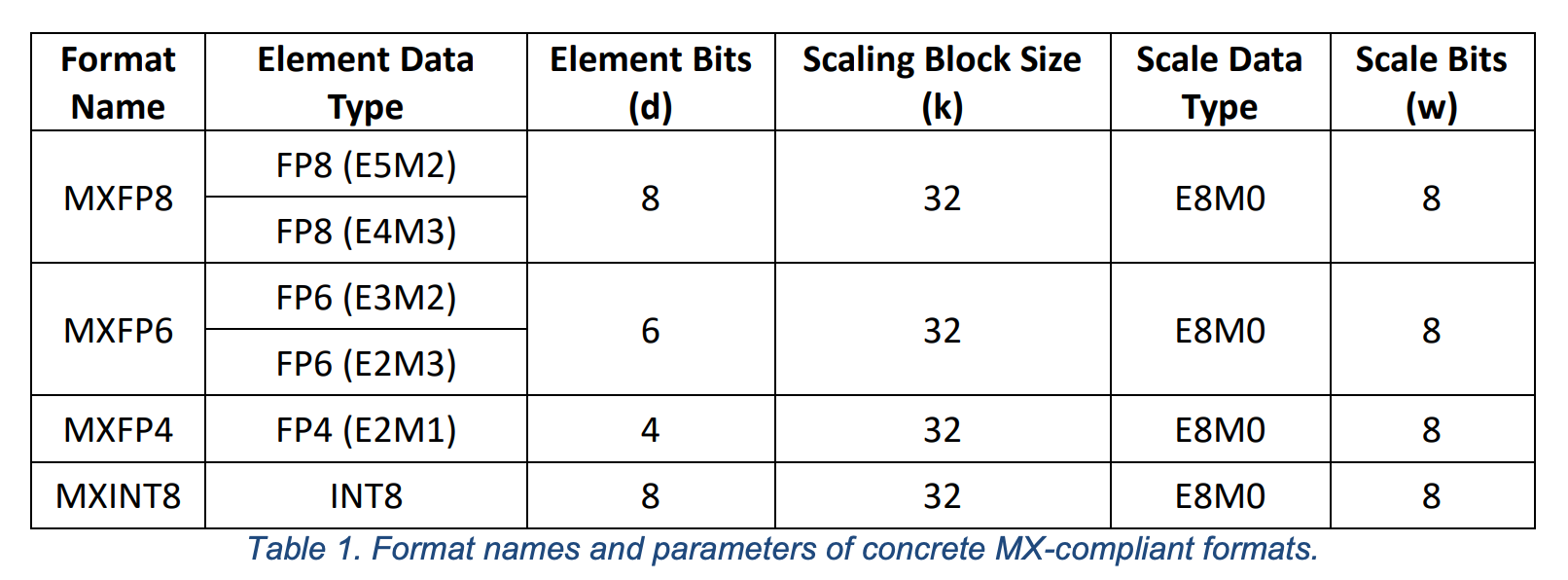
OCP has been busy and in September 2023 published the version 1.0 of the OCP Microscaling Formats (MX) Specification. This standard introduces the MX scaling formats and defines 4 examples (concrete MX formats): MXFP8, MXFP6, MXFP4, and MXINT8, with two variants each for the element data types for MXFP8 and MXFP6:
In the MX scaling formats, the scale factor, is factorized across a block of elements: k elements. This scale factor acts as an supplemental exponent. This saves storage space and trades it off with the accuracy of the block dynamic range.
The total storage is d*k+w bits. For MXFP8, a k=32 block occupies 264 bits of storage (33 bytes). For MXFP4, the storage requirement goes down to 136 bits (17 bytes).
During conversion from a vector of k scalar elements to a MX scaling block, the scale factor is selected such that the maximum scalar element is encoded with a stored element that has the maximum element type exponent (this maximize the range of values which can be stored without loss of accuracy, assuming no value overflows).
MX scale factor format: E8M0
MX scaling format currently only specifies E8M0 for compliant scale factor format.
This 8-bit format uses the value 127 as exponent bias and reserve the value 0b1111_1111 for NaN. There is not encoding for “infinity” exponent. And the scale factor value does not imply that the elements it applies to are normal nor subnormal (this information is fully encoded in the element data type itself).
There are two conditions under which an encoded element can be a special NaN value: if the shared scale factor is 0b11111111 or if the scalar element is a NaN. In the former case, all k elements in the block are NaNs. The latter case is not possible if the scalar element format does not offer any NaN encoding.
Maximum value
MX scaling format mandates that any encoded value (2^scale.scalar_element) be within the IEEE754 binary32 (single precision) range. If that is not the case, then the behavior is implementation defined. The standard does not mandate to be able to support numbers which cannot be expressed in single precision exactly.
MX scaling format block

The share scale factor acts as a second-level of exponent for MXFP(8/6/4) and as a shared exponent for MXINT8.
Element Data Types
Let us now dive into the details of the floating-point formats available for the MX Scaling scalar element storage.
The following sections contain a few Cheatsheets initially shared as notes on Substack. Those cheatsheets aim at gathering the key information about each floating-point open compute project formats.
8-bit Floating-Point: OFP8, E5M2 and E4M3
OCP defines 2 8-bit floating-point formats: OFP8 E5M2 and E4M3. Those formats were specified before the MX scaling standard, as part of the OCP 8-bit Floating Point Specification (OFP8).
They encode more special values than other scalar element formats used in MX, in particular both offer Not a Number (NaN) encodings and E5M2 even offer infinity encodings.
6-bit Floating-Point: FP6, E2M3 and E3M2
Neither FP6, nor FP4 offer any special value encodings (NaN and Infinity cannot be represented in those scalar formats).
In MX-FP4 and MX-FP6, You can encode a infinity block with an infinite scale factor (and same for NaN) but it is not really practical to encode infinity in a subset of elements.
4-bit Floating-Point: FP4, E2M1
4-bit floating point encoding is minimalistic as there is not a lot of space to encode value anyway. The format does not offer any special value encoding. For each sign value, there is a zero encoding and a single subnormal value (corresponding to 0.5). The other 6 encodings per sign value are used for normal value. The range is really limited (from -6.0 to 6.0) and the significand can only take 3 possible values (excluding zero but including normal and subnormal cases).

8-bit Integer: INT8
The concrete MX scaling format is more of a fixed-point format since it assumes an implicit scaling factor of 2^-6. It uses 2’s complement encoding and allow the largest magnitude negative encoding to be left unused (corresponding to -2) to conserve symmetry, since 2.0 cannot be encoded.
Note: the MXINT8 is not equivalent to a BFloat16 encoding with shared exponent. Indeed, because there is no implicit digit depend on the value of the (shared) exponent, a bit of significand accuracy is lost compared to what would have been required to encoded a BF16 value between the scalar element and the shared exponent. For example, no BF16 value with an odd mantissa can actually be encoded in MX INT8 (scalar element) + E8M0 (scale factor) format.

Quirks of the MX scaling format specification
MX scaling specification authorizes a few implementation defined behaviors, the most notable are summarized below:
If the product of the scale factor times the scalar elements fall outside of the range representable in single precision
Conversion of a NaN input to the FP6, FP4, or INT8 format for scalar elements
Support for -2.0 encoding in INT8 format
What about the data layout ?
The MX scaling specification does not mandate how a block should be stored, leaving this at the discretion of the implementation. The standard does not mandate how the block should be mapped with respect to the application data layout. For example, for an application working on 2D matrices, should the exponent be shared among k row elements, k column elements, a k * k tile1 ? Depending on which primitive is implemented (e.g. outer product vs inner product), it may benefit from different block layout.
Is there already support for MX scaling formats ?
With OFP8 and the MX scaling formats the Open Compute project is leading the effort to standardize small formats. This initiative, mostly driven by AI needs, has taken foot in the ecosystem with already hardware support. It is not clear when the IEEE response (started with the P3109 workgroup) will converge to a specification, nor whether this specification will be adopted.
The original OCP MX Scaling was backed by AMD, Arm, Intel, Meta, Microsoft, NVIDIA, and Qualcomm.
NVIDIA has offered hardware support for OFP8 since at least the Hopper generation of its GPUs and offers MXFP4 support since the Blackwell generation. NVIDIA Blackwell also offers support for MXFP6 but without raw performance benefit over MXFP8 (which could indicates that MXFP6 is supported by the same datapath as MXFP8, with the same number of elementary operations) whereas MXFP4 raw throughput is double that of MXFP8.
According to ARM developper documentation: “FP8 support is introduced as optional feature from Armv9.2-A”. This support covers both E4M3 and E5M2, the distinction is made through the Floating-Point Mode Register (FPMR) which also encodes which saturation mode is enforced for conversions and which mode is enforced for other operations (2 different bits control those settings independently). ARM offers both conversions and arithmetic instructions (dot-product, multiply-add, sum of outer products) with a focus on accumulating on half precision precision.
RISC-V and MX scaling formats
RISC-V has a few on-going instruction set extension projects to support OFP8 (Zvfofp8min) and OFP4 (Zvfofp4min). There is no project to support OFP6 at the moment (April 2025). The extension projects are limited to offering conversions.
Zvfofp8min offers conversion between OFP8 and BF16 (both directions), and from FP32 to OFP8 (only quad narrowing conversion). The narrowing conversions support both saturate and non-saturate modes (as mandated by the OFP8 standard). Both OFP8 formats, E4M3 and E5M2, are supported. The distinction is made through the vtype.altfmt bit introduced in the Zvfbfa proposal (0: E4M3, 1: E5M2).
Note: to distinguish OFP8 formats, the use of the CSR bit
vtype.altfmtrather than multiple opcodes has sparked some discussions on the mailing list. On one hand, it uses a standard control path on any RVV implementation (vtypealready control which format size is selected) and limit the number of new instruction encoding required. On the other hand, if they are application which requires very frequent (like in the same loop body) switch from one OFP8 format to the next, this solution could be more costly in term of extra instructions. This could have a performance impact for narrow processor implementations. At the moment, it does not seem like switching frequently is a requirement, but as usual, if you have argument against this please reach out on the RISC-V vector SIG mailing list.
Zvfofp4min defines widening conversion from OFP4 to OFP8. The assumption is that OFP4 is mostly used for parameter storage, and not storage of activations after quantization. Only E4M3 is targeted. The rationale is as follow: the single OFP4 format can be exactly converted to both OFP8 formats, but OFP6 formats requires OFP8 E4M3 to convert exactly from E2M3, and so E4M3 was selected as the single destination.
The figure below summarized Zvfofp4min (version 0.1) and Zvfofp8min (version 0.2.1).

Content of both Zvfofp8min and Zvfofp4min is still being discussed at time of writing (April 2025). Feel free to contribute any dissident (or concurring) opinion on RVIA vector-sig group: https://lists.riscv.org/g/sig-vector.
No dedicated support for the scale factor part of the MX scaling formats is offered by RISC-V at the moment. Neither are any arithmetic operations on OFP8 / OFP4 offered.
What’s next ?
OCP MX Scaling Formats answers a real request for standardization of lower precision floating-point formats. Those formats seem particularly well suited for machine learning applications but may see application elsewhere. The number of networks using OFP8 is already noticeable and although OFP4 does not boast the same number yet, we are seeing large language models exploiting the smaller MX scaling format (e.g. this NVIDIA’s version of DeepSeek R1: https://huggingface.co/nvidia/DeepSeek-R1-FP4). Given the performance and storage boost, it is likely that investment into those small formats is going to continue and more and more hardware are going to be available, making their adoption worthwhile.
Reference(s):
Microscaling Data Formats for Deep Learning (pdf article)
OCP Microscaling Formats (MX) Specification version 1.0 (pdf)
IEEE P3109 working group and its public github.
The standard does not prevent sharing the exponent among blocks larger than k elements
Unfortunately, I am unable to provide it.