
RISC-V Scalar Bit Manipulation Extensions
Zba, Zbb, Zbc, Zbs, Zbkb, Zbkc, Zbkx and B extensions

On March 25th 2024 (announcement) the public review period for RISC-V B extension ended and it should be ratified soon. We want to use this occasion to present RISC-V ISA offerings in term of scalar bit manipulation.
Bit manipulation in a Nutshell
Bit manipulation refers to many different operations (from rotation to single bit manipulation) which can require a long sequence of instructions if not supported natively by an ISA. For example, simply extracting the value of a single can require shifting and masking, and counting the number of bits set (a.k.a. popcount) can require many more instructions (see https://www.johndcook.com/blog/2020/02/21/popcount/ and for a comprehensive reference, the interested reader can refer to the well known book Hacker’s delight).
RISC-V extensions for bit manipulation (often referred to as bitmanip) were ratified in November 2021. bitmanip is often labelled as a collection of extensions since it groups 4 extensions: Zba, Zbb, Zbc and Zbs

Zba: address generation
Zba is made of 8 instructions which can be used to speed-up memory address generation, performing the work of multiple basic instructions.
For RV32, Zba introduce 3 shift-add-add instructions: sh1add, sh2add, and sh3add. They shift one of their operand, rs1, by 1 (respectively 2 and 3) bit left before adding the result to the second operand rs2. The shift perform a multiplication by a power of two, assisting in the computation of a half-word (16-bit), word (32-bit) or double-word (64-bit) address.
Those instructions are also defined for RV64, in both case they are defined as operating on XLEN-wide values. In addition to those 3, Zba for RV64 introduces 3 unsigned word variants: sh<n>add.uw (n=1, 2, 3), which only considers the least significant 32-bit word of rs1, which is zero extended to XLEN before being shifted by n and added to rs2. Finally, Zba for RVA64 introduces unsigned-word versions of add and slli (shift-left-logically by a 5-bit immediate): add.uw and slli.uw.
Zbb: basic bit-manipulation
Zbb introduces the following instructions:
logic with negate:
andn,orn,xnorcount of leading or trailing zeros:
clz[w],ctz[w]pop(ulation) count:
cpop[w]minimum / maximum for signed and unsigned integers:
min[u],max[u]sign and zero extensions:
sext.(b,h),zext.hrotations:
rol[w],ror[i][w]or-combine Byte:
orc.bbyte reverse:
rev8
All these instructions could be expanded into sequences of simpler instructions from the base ISA, their introduction provides sizable code size reduction.
The instructions with a w suffix are only defined for RV64. They work on the least 32-bit word on their inputs and sign extend their 32-bit result to XLEN bits. All other instructions work on XLEN-bit wide operands.
andn and orn invert one of their operand while xnor inverts the result of a xor operation.
orc.b set each byte of the result to 8b11111111 if any bit in the corresponding byte of the operand is set and 8b00000000 otherwise.
Note: We have presented the vector version of Zbb, Zvbb, in this post:
orn,xnor, andorc.bare not present in the vector extension Zvbb.

Zbc: carry-less multiplication
Zbc defines 3 new instructions: clmul, clmulh, clmulr.
Those instructions perform various forms of carry-less multiplication. A carry less multiplication is a binary multiplication where accumulation of similarly weighted partial products is performed by XOR operation rather than integer addition (hence the name carry-less since XOR does not generate any carry). It is equivalent to assuming each input is a polynomial with boolean coefficients (in GF(2)) and the carry-less multiplication corresponds to the result of the polynomial multiplication.
It it used in some hash primitives such as the Cyclic Redundancy Check (CRC) and some authentication code such as the Galois Counter Mode. It often comes with a modulo reduction step which can be implemented with well crafted multiplications (e.g CRC folding).
clmul and clmulh provide everything needed to computed the full 2*XLEN-1 wide result of a XLEN-bit by XLEN-bit carry-less multiplication.
Note: multiplying a
n-bit value by am-bit value in a carry-less fashion results in a(n+m-1)-bit result. This is easy to infer in the polynomial multiplication: multiplying a degree n-1 polynomial with boolean coefficients (n-bit boolean value) by a degreem-1polynomial (m-bit boolean value) results in a degreem+n-2polynomial which is am+n-1boolean value.
clmulr provides the bit reversed high XLEN bits of the result.
Note: Some algorithms relying on carry-less multiply interpret bits in a word as little-endian when it comes to associating them with coefficient (the Least Significant Bit, a.k.a. bit 0, is the constant coefficient and the Most Significant Bit, a.k.a. bit XLEN-1 is the coefficient for X^XLEN-1), whereas other algorithms interpret the bits in a swapped order: the MSB being the constant coefficient and the LSB being the highest coefficient value. This is why both reversed
clmulrand non-reversedclmulinstructions are useful: saving a costly bit reverse operation.
Zbs: single-bit manipulation
Zbs defines 8 new instructions:
single bit clear:
bclrandbclrisingle bit extract:
bextandbextisingle bit invert:
binvandbinvisingle bit set:
bsetandbseti
Each of the instructions modifies or extracts a single bit in the input operand and copies the result to the destination register.
For every of the 4 groups, there are two variants: register index or immediate index (with i suffix); the index of the modified/extracted bit can either be stored in a register (rs2) or directly in the opcode as a 5-bit immediate (RV32). For RV64, the opcode dedicates an extra bit to immediate encoding, providing the 6-bit value required to encode any bit position in a 64-bit (XLEN) register.
The B extension
The B extension, not yet ratified as of April 5th 2024, does not introduce any new instructions. It is simply a grouping of 3 of the existing, and already ratified, ISA extensions specifying bit manipulation instructions: Zba, Zbb, and Zbs.
Zbc is not part of the B extension. Although it can be very useful for any application using carry-less arithmetic but it implies the implementation of a XLEN x XLEN carry-less multiplier whose large cost may be too high for some processors.
Note: the B extension also specifies that bit 1 of the
misaCSR describes support for the B extension: if the bit is set the implementation supports the extension, if not then it may not support it.
The very minimal B extension document can be found here: pdf for version 1.0-rc2. It is a very quick read (a single chapter and a single section).
The B extension was designed to group in a single extension the most common scalar bit-manipulation extensions. Those 3 extensions are mandatory in the standard RVA23(U64) and RVB23(U24) profiles.
Bit manipulation and cryptography
Some instructions introduced in RISC-V scalar bit manipulation extensions are reused in RISC-V scalar cryptography extensions: Zbkb and Zbkc.
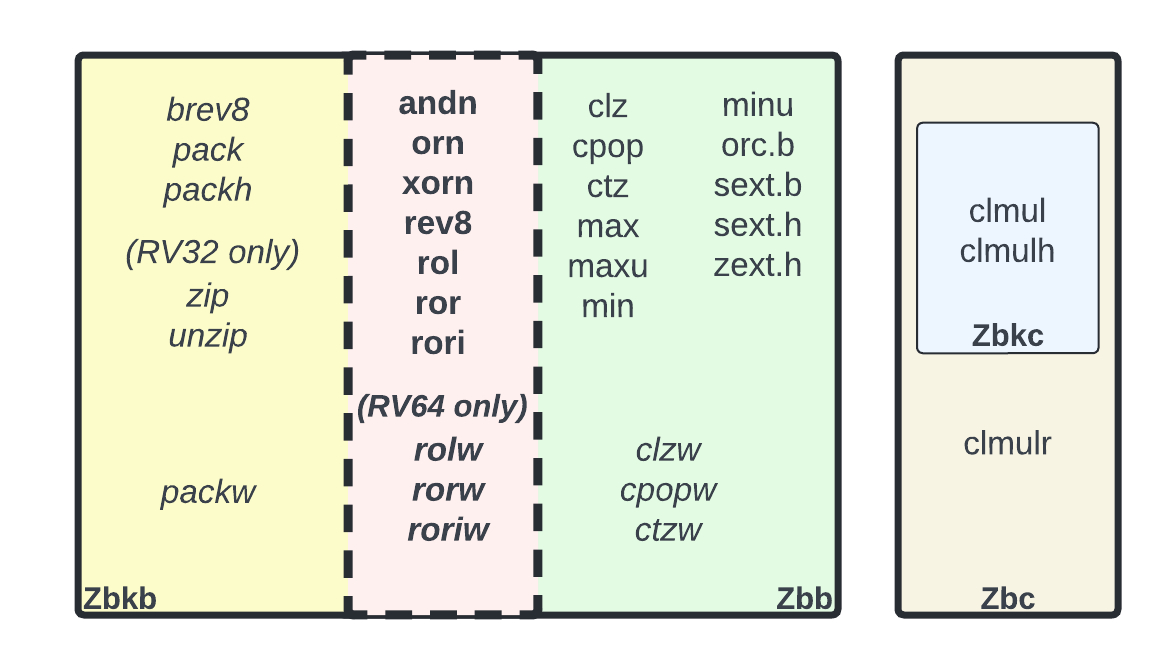
Bitmanip for cryptography: Zbkb extension
The extension Zbkb integrates some of Zbb instructions (andn, orn, xnor, rol*, ror*, and rev8)and add a few new ones:
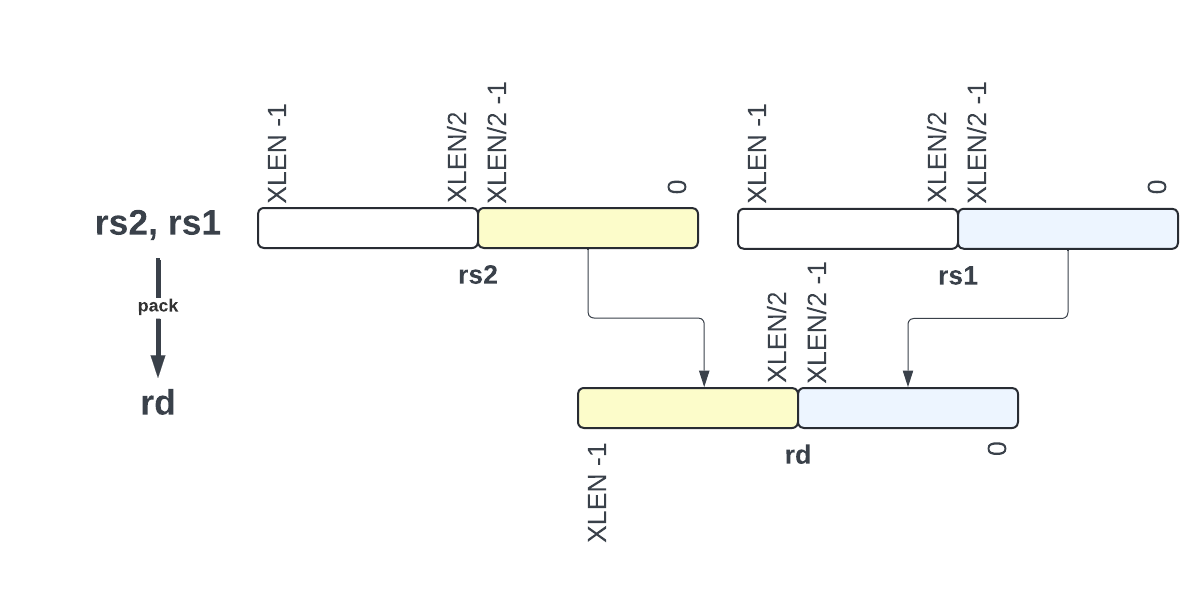
XLEN/2 word, byte and half word packing:
pack,packh,packwbit in byte reversal:
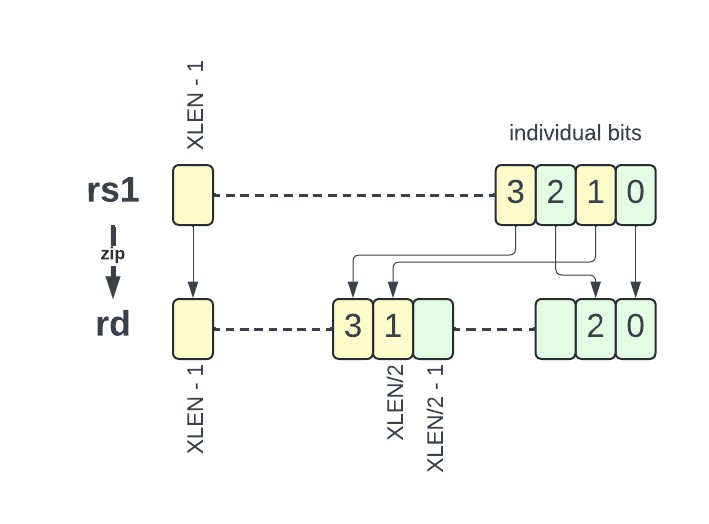
brev8splitting odd/even bits:
zip, and its reversal:unzip(RV32 only)
The figures below illustrates the instructions which are in Zbkb but not in Zbb.

Carry-less for cryptography: Zbkc extension
The extension Zbkc reuses clmul and clmulh from Zbc (but not clmulr).
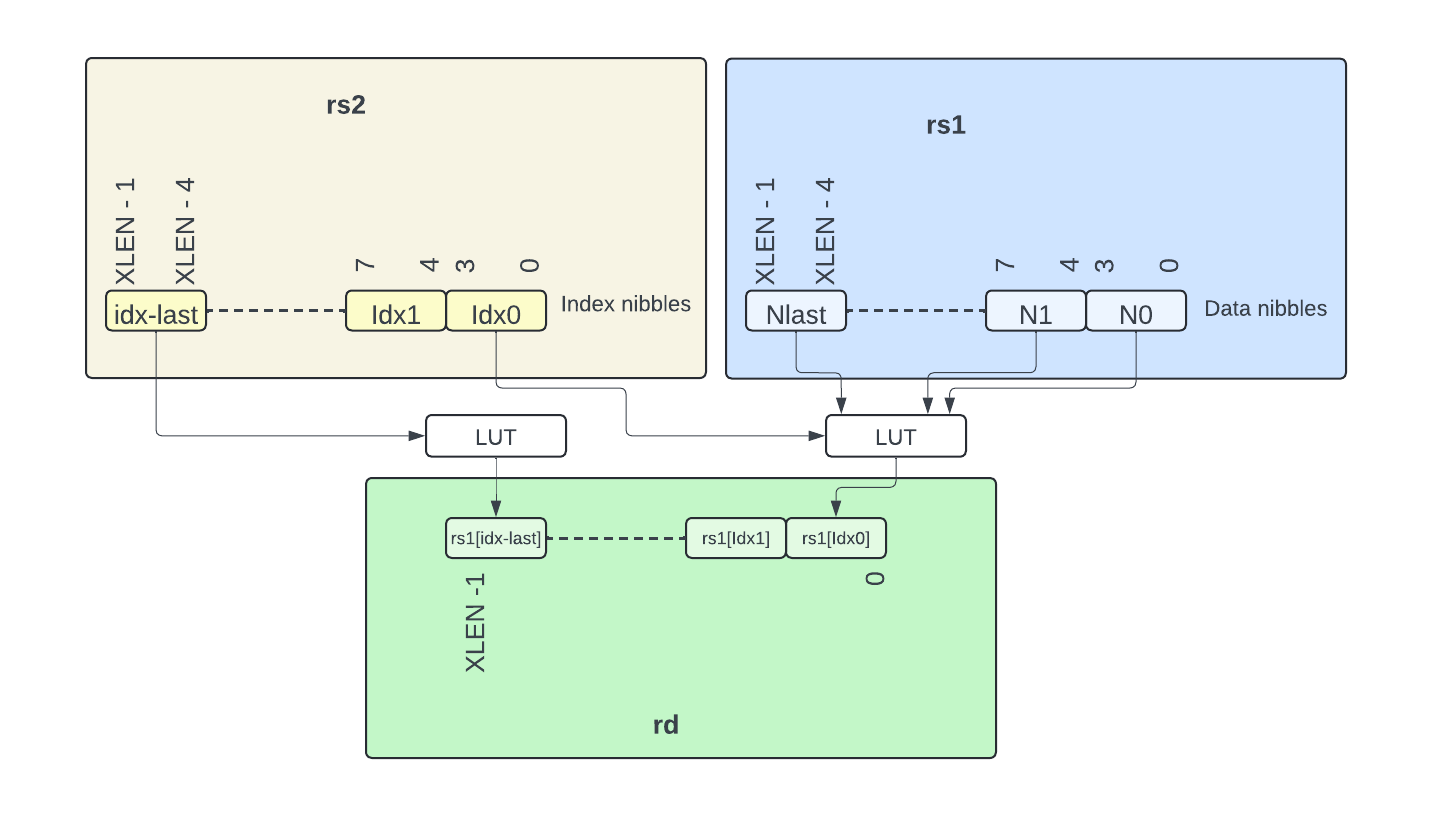
Crossbar permutation instruction: Zbkx
Another set of cryptography bitmanip instructions not defined in any of the scalar bitmanip extensions is the set of permutation instructions introduced in Zbkx. There are two such instructions: xperm8 and xperm4. xperm8 performs a byte permutation and xperm4 performs a nibble (4-bit element) permutation. Both instructions read their data set from source rs1 and their index vector from source rs2.
For xperm4, a 4-bit index is enough to address every data nibble when XLEN=64; in such a case every index has a mapping in the data set rs1. For xperm8 8-bit indices or for xperm4 when XLEN=32, the index may be out-of-bound: in such case the result element is replaced by 0.
Scalar bitmanip and constant execution time
The scalar cryptography extension adds Zkt: extension mandating constant time execution latency. Zkt covers all instructions from Zbkb, Zbkc, and Zbkx: when Zkt is supported all those instructions must be implemented with data-independent execution latency, as to not disclose any information on data values through data-dependent latencies. This is critical for any cryptography application. Zkt does not mandata data-independent execution latency for other scalar bitmanip instructions (In Zba, Zbb, Zbc, Zbs but not Zbkb or Zbkc) but it does cover other standard instructions.
Conclusion
Scalar bit manipulation extensions extend RISC-V capability to implement widespread operations on bits which would require large sequence of instructions otherwise. Implementing those extra instructions incur extra costs compared to the base ISA but this cost is easily justifiable for most applications in particular for the 3 (out of 4) extensions (Zba, Zbb, Zbs) which are grouped into the B extension. The B extension is mandatory in the main RISC-V profiles such as RVA23U64 (while Zbc remains an option in the profile). An extra set of scalar bit manipulation instructions has also been specified, those extensions cover more dedicated needs and can be mandated to be implemented with data independent execution latency to make them suitable for use in cryptographic applications.
References:
RISC-V Bit-Manipulation ISA-extensions (specification)
Repository for bitmanip specifications: https://github.com/riscv/riscv-bitmanip
Repository for B extension specification: https://github.com/riscv/riscv-b
Tracking RISC-V B extension ratification on RVIA Jira: RVS-2006 ticket