
RISC-V Vector Cryptography Extension (2/2)
Hash, bitmanip and conclusion

June 24th 2023 Update: the vector cryptography specification has recently reach the public review stage and a few differences have been introduced since this post was written. A summary of those changes can be found in the following post:

In this second post about RISC-V vector cryptography extension (first one is accessible here) we review the instruction dedicated to hash functions and bit manipulations.
Note: except instructions in Zvkb, vector crypto instructions are only defined as unmasked (opcode’s bit 25 set to 1). The encoding for the masked variant is reserved. It is not possible to use the mask operand v0 to select which element (group) are active: all elements inside the vector body are active.
Hash
Zvknha and Zvknhb: SHA2
The new standard introduces two sub-extension implementing NIST Secure Hash (SHA-2) algorithm. They contain the 3 same instructions but with different set of supported element width. Zvknha is a subset of Zvknhb: Zvknha brings support for SHA-256 and Zvknhb brings support for both SHA-256 and SHA-512. It is not possible to have only support for SHA-512. All instructions work on 4-wide element groups of either 32 or 64-bit elements.
The 3 new instructions are:
vsha2ms.vv: message schedule expansion for SHA-2, performs SHA-512 message expansion if SEW is 64 and SHA-256 if SEW is 32, it produces 4 new SEW-wide word in the SHA-2 message schedule.vsha2cl.vvandvsha2ch.vv: hash compression, computes a couple of rounds of SHA-512 (SEW=64) or SHA-256 (SEW=32). Both instructions expects an element group containing 4 message schedule word per group in their vs1 operand;vsha2cloperates on the least 2 significant words andvsha2chon the most 2 significant word in the element groups.
Note:
vsha2cl.vvandvsha2ch.vvassume that theirvs1 operandcontain words from the SHA-2 message schedule (expanded byvsha2m.vv) added with round constants. None of the Zvknh instructions perform the addition which must be implemented in software using other RVV instructions (e.g.vadd.vv).
Zvksh: SM3
Zvksh defines two instructions to perform Shang-Mi 3 hash function. The instructions uses an EGS of 8 and expects a SEW=32-bit.
The 2 new instructions are:
vsm3me.vv: message schedule expansion for SM3, performs SHA-512 message expansionvsm3c.vi: message compression for SM3, performs two rounds of SM3 hash
Shang-Mi is defined as operating with big-endian byte ordering. To match RISC-V default little endianness, both vsm3c.vi and vsm3me.vv perform a word byte swap of their input data and their result.
Bitmanip
The Zvkb extension contains various instructions to perform different bit manipulation. Contrary to the other extensions in the vector cryptography specification they do not work on element groups and so all standard values of vl and vstart are valid. Also most operation can be masked.
Bit and Byte reversal.
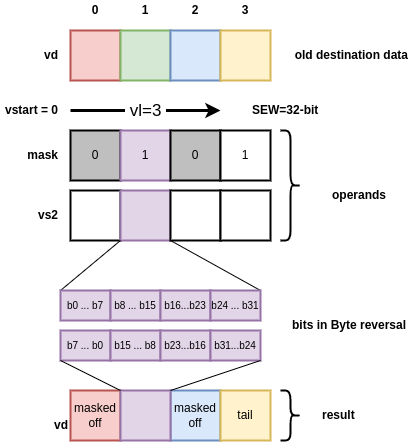
vbrev8.v performs a bit in byte swap: the order of bits in each byte is independently reversed. It admits all SEW values supported by the implementation, they affect the operation through vl (the number of byte bit-swapped is vl * SEW / 8) and through the mask operand (when masked): each mask bit determine if the corresponding SEW / 8 must be bit-swapped or follow mask policy (undisturbed/agnostic). The effect of vbrev8.v on an active element is illustrated by the Figure below (with bits in byte appearing with LSB on the left and MSB on the right).
vrev8.v performs a byte in word swap: for each active SEW word (masked-on and part of the vector body) the word bytes are swapped within the word. The effect is illustrated on the Figure below (the order of bits in Bytes is kept unchanged).

When SEW=8-bit,
vrev8.vhas no effect on active elements and when SEW=16-bit, it is equivalent to a rotation by 8 (in whatever direction).
Vector Rotations
Zvkb contains 2 vector rotations:
vrol.vv/vrol.vx: vector rotate leftvror.vv/vror.vx/vror.vi: vector rotate right
All the vector rotation instructions affect all active SEW-wide elements (not masked and within vector body).
Note: there is no
vrol.viversion of vector left rotate because it is redundant withvror.viwhose encoding has been specified to provide a 6-bit immediate, enough to encode every possible rotation for all SEW up to 64-bit. This solution was chosen because it permits the standard to offer an immediate rotation by 32 (useful for SEW=64) which would have not been possible with 5-bit immediates.
Carry-Less Multiply
Carry-less multiplications are multiplications of polynomials with boolean coefficients (in GF[2]). This operation is used to implement some cipher modes such as the Galois Counter Mode (GCM), if Zvkg is not available, CRC and other cryptography primitives.
Zvkb contains 2 vector carry-less multiply instructions:
vclmul.vv/vclmul.vx: vector carry-less multiply, low partvclmulh.vv/vclmulh.vx: vector carry-less multiply high part
In the current standard version, those instructions are only defined for SEW=64-bit.
Note: the result of the carry-less multiply of two SEW-bit wide elements is a (2*SEW-1)-wide result, so the most significant bit of every active result element of
vclmulh.v*is always 0
Miscellaneous
The last instruction introduced in Zvkb is vandn, this is a bitwise vector and-not which negates its vs1 operand (vandn.vv variant) or rs1 operand (vandn.vx) variant; and then AND the result to its vs2 operand. It was introduced to accelerate SHA-3.
Note: Until one of the last specification drafts
vandnused to negate itsvs2operand and had avandn.vivariant. Negatingvs1/rs1was more in line with other RISC-V extensions and thus the instruction behaviour was modified, making the.vivariant useless (since it can now be implemented withvand.vi).
Note (June 24th 2023 Update): After the writing of this post Zvkb was changed. In version 1.0.0rc1 (frozen) of the specification it has been split between Zvbb and Zvbc and new instructions were introduced; more details can be found in this post.
GHMAC
Zvkg contains 2 instructions performing vector multiply or accumulate-multiply of polynomial in GF(2^128) with reduction as defined in the GHASH method of the GCM (Galois Counter Mode) cipher mode.
vghsh.vv: accumulate-multiplyvgmul.vv: multiply
Both those instructions work on 4-element groups (EGS=4) with SEW=32, similar to cipher instructions from AES and SM4 extensions they are going to be used with.
The most useful instruction is vghsh.vv because it performs both the initial xor between the previous hash and the new ciphertext and the multiplication by H (H is the encryption of 0 with the current cipher key).
Note: several version of those instructions have been considered during the specification discussions. In particular an early draft defined
vghmac.vv, a multiply-and-accumulate version of vghsh which was discarded because of lack of encoding space and because vghsh operation ordering is a better fit to integrate existing software codebases implementing GCM (e.g. linux kernel and OpenSSL).
Encoding and opcode space
The vector cryptography extensions encodings are overlaid on top opcode spaces:
Zvkb uses the OP-V opcode space, the same as the standard version instructions from RVV 1.0: the opc fields (opcode[6:0]) is equal to 0x57
All other extensions: Zvknh[ab], Zvkned, Zvkg, Zvksed, Zvksh use the OP-P opcode space: the opc fields (opcode[6:0]) is equal to 0x77
There is currently no compressed version (16-bit opcode) of vector cryptography instructions (nor of any vector instruction for that matter)
Note: this choice makes the vector crypto extension(s) (except Zvkb) incompatible with the future P extension (packed SIMD). As P is not intended to be used alongside V, this should not be a big constraint for implementations
Conclusion
The new RISC-V vector cryptography extension should enter public review in Q1 2023. You can go to riscv.org and join the community to provide feedback on the upcoming specifications. Some late modifications may still happen as the standard is still under review by RVIA Architectural Review Committee. We will update this post (and the previous one) with any notable change. The community has been working on integrating this new extensions into OpenSSL (in particular Christoph Müllner from VRULL) and into the Linux Kernel: both software codebases should benefit from vector crypto acceleration as soon as an implementation is available with a sensible performance uplift with respect to generic RV64G or even RISC-V scalar cryptography extensions Zk*. It is mandated that all vector cryptography instructions be implemented with data independent latencies and the crypto task group is considering extending that requirement to standard vector instructions useful to implement cryptography primitives.
The superset of extensions Zvkng (NIST algorithm suite with GHASH instructions) and Zvksg (Shang-Mi algorithm suite with GHASH instructions) will be integrated as optional to the future RVA23 profile for application processors and may become instrumental in RISC-V future.
If you have missed our first post on RISC-V vector cryptography extension, we can access it below:
