
RISC-V Vector Extension in a Nutshell (Part 4): permute operations

This article is part 4 of a series on RISC-V vector extension, and focuses on permute operations.
Part 1, Introduction, is accessible here; part 2, review of arithmetic operations there; part 3, survey of operations with or on masks there.
SIMD and Vector instructions sets needs to offer permutation instructions to allow the programmer to manipulate and re-organize data within vector registers. RVV 1.0 offers such instructions in multiple flavours, we will review the permutation instruction families in this post and provide some illustrations.
Full Permute
The most generic operation is the full permute, which is also the most operand consuming as it often requires a full vector operand for indices and the most expensive in hardware. RVV 1.0 specifies two flavors of full permutes: vrgather.vv and vrgatherei16.vv.
The first one, vrgather.vv, accepts an index vector with indices as wide as the data elements (SEW).

The second variant, vrgatherei16.vv, uses 16-bit wide indices whatever the SEW. 16-bit is enough to contain an index for the largest possible vector (LMUL=8, SEW=8-bit, VLEN=65536). This variant is useful to save index space when manipulating large elements and to unify the index management.
Note: vragtherei16.vv has index elements wider than data elements for the SEW=8 case, this means that EMUL for the index operand is twice the value of LMUL, or EMUL for the data operand.
Vector Splat
RVV 1.0 defines two indirect splat instructions: vrgather.vx and vrgather.vi, both of them replicate an element to all the active result elements, the replicated value is selected in the data source from the index read from a scalar register (vrgather.vx) or from an immediate in the opcode (vrgather.vi).
These instructions can be implemented with much less hardware than the full permute.
Vector Slide
https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#163-vector-slide-instructions
RVV 1.0 specifies simple slide permutes: the input vector active elements are translated by some amount:
vslide1up.vx translates the element by 1 index up and insert a value read from a scalar integer x register in the least significant element position (index 0)
vslide1down.vx translates the element by 1 index down and insert a value read from a scalar integer x register in the most significant active element position (index vl - 1)
vslideup.v[xi] translates the element by <n> index up and leaves the n lowest elements undisturbed. <n> is either read from a scalar register (.vx) or an immediate (.vi)
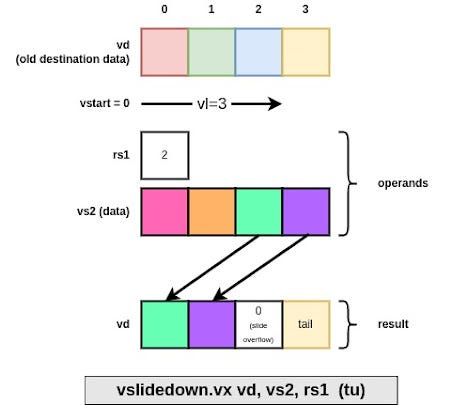
vslidedown.v[xi] translates the vl active element by <n> index down, any element which should have been read outside the source group is replaced with 0s. <n> is either read from a scalar register (.vx) or an immediate (.vi)
There exists floating-point versions of the vslide1* instructions: vfslide1up.vf and vfslide1down.vf, which read the inserted element from the scalar floating-point register file (f registers).
Vector Compress
RVV 1.0 defines a compression/group instruction: vcompress.vm, this instruction extract active elements from a vector source operand vs2 based on a mask in vs1 and group the extracted elements in the least significant elements of the result.
Note: vcompress.vm uses a slightly different definition of tail: the tail size is the number active elements subtracted from the total number of elements in the destination vector group. As they are always less active elements than vl (or as many as vl) the vcompress.vm can be longer than a standard tail. The tail result elements follow the tail policy setting.
%3CmxGraphModel%3E%3Croot%3E%3CmxCell%20id%3D%220%22%2F%3E%3CmxCell%20id%3D%221%22%20parent%3D%220%22%2F%3E%3CmxCell%20id%3D%222%22%20value%3D%22%22%20style%3D%22rounded%3D0%3BwhiteSpace%3Dwrap%3Bhtml%3D1%3BstrokeWidth%3D2%3BfillColor%3D%23B266FF%3B%22%20vertex%3D%221%22%20parent%3D%221%22%3E%3CmxGeometry%20x%3D%22400%22%20y%3D%22230%22%20width%3D%2250%22%20height%3D%2250%22%20as%3D%22geometry%22%2F%3E%3C%2FmxCell%3E%3C%2Froot%3E%3C%2FmxGraphModel%3Evv

Conclusion
RVV 1.0 specification also lists the whole register move operations as part of the vector permute instructions.
There are 4 such instructions: vmv1r.v, vmv2r.v, vmv4r.v, vmv8r.v. These instruction are not impacted by the vtype.vlmul parameter value: EMUL is directly encoded in the opcode. Similarly, the effective vl value evl is defined by VLEN / SEW * NREG, where NREG is the EMUL size encoded in the opcode.
Those instructions are used to copy the vector register file efficiently without needing to modify the vtype parameter values.
All those permutation instructions are really handy to manipulate elements in registers. They can also be used to implement small size lookup table, load value to vector register from the scalar register files ...
Reference:
"Vector Permutation Instructions" section of RVV 1.0 specification: https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#16-vector-permutation-instructions