
RISC-V support for BFloat16
Fast track extensions Zfbfmin, Zvfbfmin, Zvfbfwma

Brain Float 16
The IEEE-754 standard defines floating-point number formats, their encodings and the numerical behavior of operations on those formats. Those formats (in particular binary floating-point formats) are ubiquitous in modern CPUs, GPUs and TPUs. They are used for a very wide range of applications (scientific computing, finance1, graphics …). The standard formats include single (binary32) and double (binary64) precisions: 32-bit and 64-bit binary floating-point formats providing different compromises between accuracy and cost: single provides less bits of precision (normal binary32 significands are 24-bit wide compared to double’s 53 bits) and less dynamic range (normal binary32 exponent range of [-126, 127] vs [-1022, 1023] for binary64) but single requires less silicon area, is less power hungry and can fit more data in the same register / bus width, improving throughput of parallel operations (SIMD/Vector/Matrix).
The standard also defines smaller formats, including the 16-bit wide half precision, a.k.a. binary16, which used to be dedicated to storage and has been used more recently as a computation format in particular in machine learning (often combined with mixed precision binary32 accumulation). Machine learning applications, in particular training, require formats with more dynamic range than half precision (whose exponent range is [-14, 15]) but without needing as many significand storage bits as single precision (23).
Thus came Brain Float 16 (a.k.a. BFloat 16 or BF16), a format initially conceived by Google Brain research team2 . BFloat16 keeps the dynamic range of single precision (8-bit exponent, same bias) but provides a smaller significand (7-bit mantissa). The BFloat16 format corresponds to the 16 most significant bits of the IEEE-754 binary32 encoding as represented by the diagram below3:
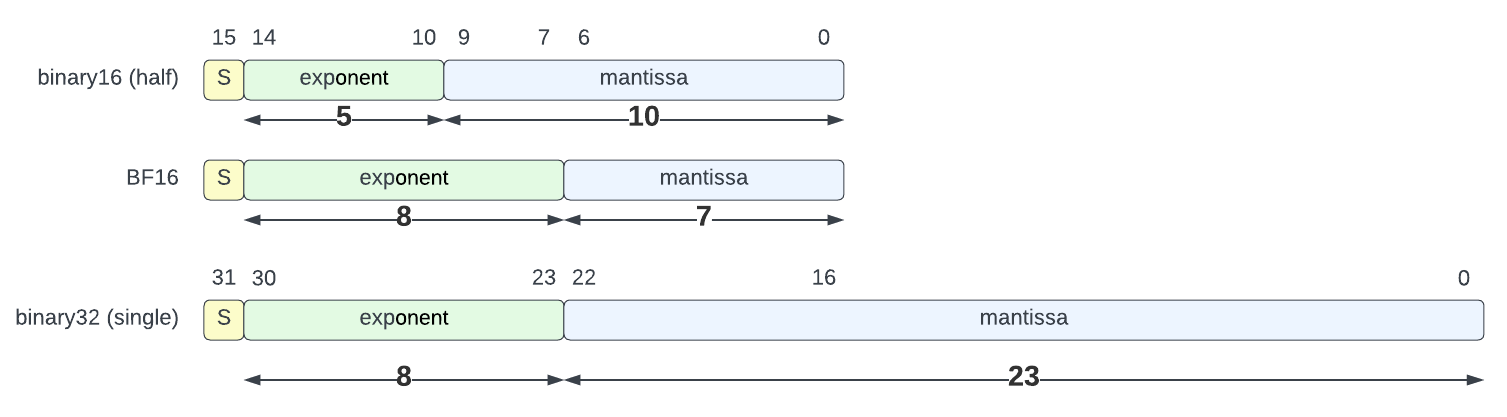
BFloat16 has been widely adopted and is implemented in many processing units doing machine learning (Intel’s Nervana, Arm4, NVIDIA5, …) and is now considered a must-have for this application domain.
RISC-V and BFloat16
RISC-V support for single and double precision (and even quad precision) was specified very early with the F and D extensions (and Q extension). Support for half precision is more recent with the Zfh, Zfhmin,Zvfh, and Zvfhmin extensions. Those extensions were covered in this post:
Until this year (2023), BF16 was not officially supported by RISC-V. A fast track effort lead by Ken Dockser (Tenstorrent) was kicked-off to fill this void and define a new set of scalar and vector extensions to define a first version of BFloat16 support.
The effort is currently on-going and a few extensions are being considered. They are being developed as fast track extension (without a full task group supporting the effort) and are rather minimal: combined they introduced a total of 5 instructions (6 if we distinguish vector-vector and vector-scalar as two different instructions).
RISC-V BFloat16 numerical behaviour
Since BFloat16 was developed with a particular application domain in mind its numerical behavior is often tuned for better efficiency in machine learning. This means the numerical behavior often diverges from being IEEE-754 compliant (e.g. flushing subnormal inputs or outputs to zero, no implementing correct rounding and/or implementing non-standard rounding modes such as rounding-to-odd …). Although this can provide significant efficiency benefits, it makes numerical reproducibility harder since it becomes easier for implementations to chose different behaviors.
For RISC-V a fully compliant IEEE-754 behavior was selected: correct rounding, tininess detected after rounding, standard rounding modes and standard exception flags behavior are mandated for all the 5 new instructions. This implies that all RISC-V implementations will return bit identical results (similar to the floating-point behavior specified in other RISC-V extensions).
Scalar BF16 support: Zfbfmin
The first extension we consider is Zfbfmin. It is a scalar extension which defines two conversion instructions:
fcvt.bf16.s: conversion of a single precision value infs1to a bf16 value infd.fcvt.s.bf16: conversion of a bf16 value infs1to a single precision value infd.
As other RISC-V convert instructions, the 2 new operations accept a static rounding mode (encoded in the opcode) or can use the rounding mode set in the frm CSR.
As other floating-point operations, scalar BF16 instructions expects to read and write NaN boxed value when appropriate. For example if the size of a FP register is 64-bit (FLEN=64), then the BF16 value written by fcvt.bf16.s should be decoded as a NaN if read as a double or a single precision value.
Note: because BF16 and half precision formats have the same sizes (16 bits) their NaN boxing pattern are indistinguishable.
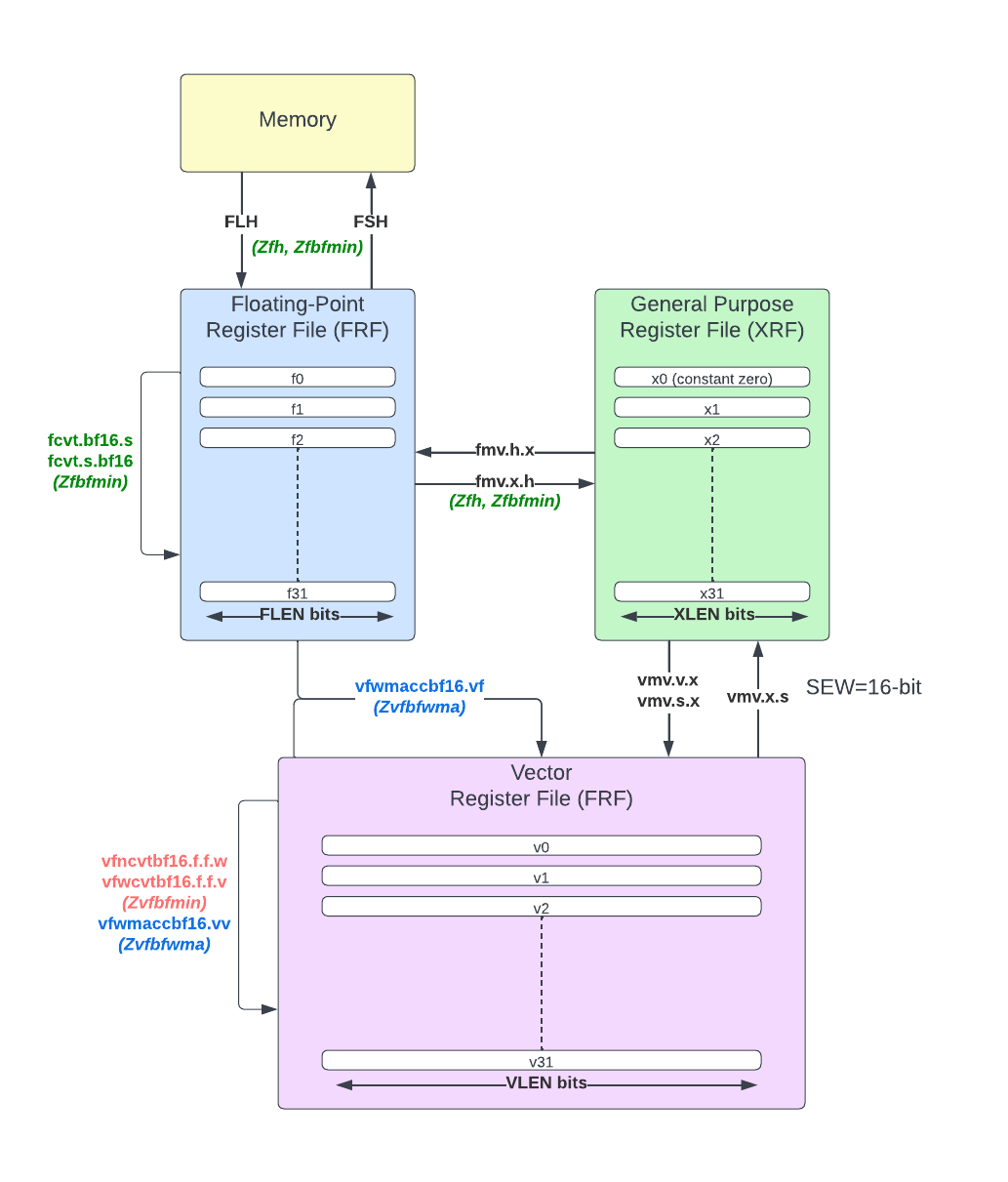
As BF16 and half precision formats share the same bit width, there is no need for Zfbfmin to introduce new data movement instructions: it simply reuses Zfh instruction flh, fsh, fmv.x.h and fmv.h.x . Their implementations alongside that of the F extension are required by Zfbfmin.
In this first BF16 scalar extension, there are no arithmetic instructions, only conversion and data movement instructions.
This reduced set of scalar instructions has two purposes:
Allowing the use of BF16 as a storage format before converting BF16 values to single precision before performing any actual arithmetic operation
Allowing the manipulation of BF16 scalar data, in particular loading into scalar floating-point registers, so they can be used as scalar operand for vector operations (e.g. for
vfwmaccbf16.vfdefined in Zvfbfwma).
Vector BF16 support: Zvfbfmin and Zvfbfwma
In addition to the scalar extension, 2 new vector extensions are introduced: Zvfbfmin and Zvfbfwma.
The first vector extension, Zvfbfmin, introduces two new conversion instructions: vfncvtbf16.f.f.w (vector narrowing convert from FP32 to BF16) and vfwcvtbf16.f.f.v (vector widening convert from BF16 to FP32). The narrowing conversion can raise any of overflow/underflow/inexact/invalid flags. The widening conversion is exact but can still raise the invalid flag if the input is a signaling NaN (in which case it will return the canonical quiet NaN as corresponding result element).
Zvfbfmin depends on Zfbfmin.
The second vector extension, Zvfbfwma, introduces a new widening FMA instruction: vfwmaccbf16.v[vf] which admits a vector-vector and a vector scalar variant. The operation is a mixed precision FMA: the product operands are BFloat16 elements and the accumulator source/destination are single precision elements. Zvfbfwma depends on Zvfbfmin.
All 3 new vector instructions are only defined if the selected element width (SEW) is 16-bit, else their encoding is reserved. They can all be optionally masked and they are sensitive to the vstart and vl values defining the active vector elements.
Note: In an earlier version of the draft specification a widening multiplication only variant of
vfwmaccbf16was specified. It has been dropped since and is no longer part of the more recent versions of the specification.
There is a linear dependency chain between the vector extensions: Zvfbfwma depends on Zvfbfmin which in turn depends on Zfbfmin (and also on the V or Zve32f extensions). If Zvfbfwma is supported then all 3 BF16 extensions are supported.
Summary
The diagram below represents the various new instructions which manipulate BF16 values alongside a few existing instructions useful to move BF16 values around (e.g. vmv.v.x with a 16-bit selected element width).
Integration in 2023 RISC-V profiles
To forecast the future adoption of an extension, it is often interesting to check in which RISC-V profile(s) it is listed and if it is mandatory or optional. Any type of listing in one of the main profiles would indicate that at least some generic software support can be expected from the ecosystem. Optional vs mandatory will determine the initial constraints generally driving widespread hardware adoption.
All 3 new BF16 extensions are listed as optional for the future RVA23U64 profile (https://github.com/riscv/riscv-profiles/blob/main/rva23-profile.adoc#rva23u64-optional-extensions) and also for the RVB23U64 profile. This means that although not all compliant implementations will instantiate such support the software ecosystem for application-class RISC-V processor should support those extensions. This corresponds well to BFloat16 applications: must-have for some machine learning tasks and not widely used anywhere else. This betrays the intent of RISC-V Application Class profile (RVA in particular) to be positioned for general purpose CPUs capable of executing with some efficiency most current workloads.

Future of BF16 Support
At the time of writing (early September 2023), the 3 new extensions have passed the Architecture Review and there are still a few steps left to go before they are ratified including a public review which will let everyone share feedback on the fast track extensions. The progress can be followed here.
RVIA Floating-Point Special Interest Group (FP-SIG) is currently discussing extending BF16 support. One of the considered options is to add generic arithmetic support in scalar and/or vector (addition, multiplication, FMAs, …). It is also likely that BFloat16 will be considered in a future matrix operation extension for RISC-V.
Overall this seems to be the beginning of RISC-V support for the BFloat16 format.
References:
RISC-V official BFloat16 specification repository: https://github.com/riscv/riscv-bfloat16
List of RVA23U64 optional extensions: https://github.com/riscv/riscv-profiles/blob/main/rva23-profile.adoc#rva23u64-optional-extensions
RVIA tracking ticket for BF16 specifications: https://jira.riscv.org/browse/RVS-704
IEEE-754 standard (2019 revision): https://standards.ieee.org/ieee/754/6210/
Sometimes in the form of decimal floating-point
The encoded mantissa size is represented, the normal significand is 1 bit wider.
Although NVIDIA is putting forward another format called TensorFloat 32 (TF32) described in this NVIDIA blog post