
RISC-V Compressed Instructions (part 2): Zc extensions

In this second blog post on RISC-V compressed extension we will review the Zc* family of extension designed to improve code size for embedded platforms (if you have not read the first part covering the C extension, it is accessible here).
RISC-V Zc* extension
Zc* is a family of 6 extensions: Zca, Zcf, Zcd, Zcb, Zcmp, and Zcmt.
Zcf, Zcd, and Zca are new labels for existing parts of the C extensions: Zcf contains the single-precision compressed load/stores (include from/to stack), Zcd contains the same type of instructions but for double precision and Zca contains every other C extension instructions.
As the C extension was covered in this post, we will focus here on the other sub-extensions.
Overview
Zcb extension
The Zcb extension contains 12 instructions: 5 load/store operations, 5 sign/zero extension operations, 1 multiplication instruction and one bitwise not.
All 12 instructions are limited to the 3-bit register addressing, targeting the subset of 8 registers (x8 - x15) defined in the C extension. They all have a single 32-bit instruction equivalent, but contrary to the C extension not all equivalent instructions can be found in the base ISA: the zero/sign extension equivalents are in Zbb (bitmanip extension) and the c.mul is in the M extension (or Zmmul). The extension of the equivalent instruction must also be implemented to allow the compressed version: for example M or Zmmul is required to support c.mul.
Zcb loads and stores bring compressed support for smaller sizes than the base C extension: while the C extension was offering only word and double word loads and stores (from/to generic addresses or only from/to the stack), Zcb offers loads and stores for bytes and half-words. Loads can sign extend or zero extend the value read from memory into the destination registers. Both load and store use memory addresses formed by adding a small immediate to a base address read from a general purpose register (no load/store limited to the stack pointer).
Zcmp: push, pop and paired register atomic move
Zcmp introduces 6 new instructions, 4 of them are specifically designed to reduce the code size of function calls and returns: push, pop, popret, popretz. Those instructions are well suited for implementation in embedded processors. Those instructions cover a a large range of common operations mandated by the RISC-V ABI when calling or returning from a function.
They bundle stack frame allocation (push) / de-allocation (pop/popret), register spilling (push) / restoring (pop/popret) and function return (popret).
The stack frame is the section of the call stack used by a function call, for example to store arguments which do not fit in registers, to save callee-saved registers when required ...
The last 2 instructions are paired register moves: cm.mva01s copies data from two registers in the s0-s7 range into a0 and a1 (the two s* can be the same register) and cm.mvsa01 copies the content of a0 and a1 into two distinct registers of the s0-s7 range. These two instructions behaviour is atomic: the intermediary state when only one of the two moves has been performed is never architecturally visible. Hence the two instructions do not expand in a single equivalent instruction or even in a sequence of two instructions which can be split or interrupted.
Zcmt: table jump
The Zcmt extension introduces support for an indexed jump to an address stored in a jump table, reducing a sequence of multiple instructions to a single instruction as long as the jump target can be stored in a 256-entry jump table.
The Zcmt extension introduces a new Control/Status register (CSR): JVT, it also adds two new instructions: cm.jt and cm.jalt. cm.jalt is an extended version of cm.jt: on top of cm.jt behaviour it links the return address to ra: copying the address of the next instruction after the cm.jalt to the ra register (to allow to return to it later)
The JVT register is a WARL (write anything reads legal) CSR register: which means any value can be written, and will not raise an illegal exception, but only legal values can be read back. This register contains a 6-bit mode field (located in the LSB) and reserved for future use, and an (XLEN - 6) bit wide base field.
If JVT.mode is a reserved value then cm.jt and cm.jalt encodings are also reserved: implementation may raise illegal instruction exception when executing them. If JVT.mode is 0, then cm.jt/cm.jalt are decoded successfully, and an index value is extracted from the 8-bit opcode bitfield located between bits 2 and 9. Both instructions shares the same opcode bit field values, the difference is made on the index value: if this index < 32, the instruction is decoded as cm.jt else it is decoded as cm.jalt.
The instruction builds a table_address as JVT.base + index << (2 for RV32, 3 for RV64) and extracts the jump target address as the content of the program memory at address table_address. The hart then jumps to that address (and link the return address to ra in the case of cm.jalt only).
This is illustrated by the following diagram, in this example the hart control flow eventually jumps to the address 0x1337 stored into the i-th entry of the jump table.

Zc* benchmark studies (spreadsheet) show up to 10% code size gain. The gain is double: transforming a sequence of up to two instructions to a single instruction and a table entry and factorizing that table entry among many different program location: the asymptotic cost when the number of call site grows becomes a single instruction.
Encoding and decoding
The encoding of compressed instructions was studied in the previous blog post on the compressed extension C. But this post did not detail how compressed instructions can be decoded from non-compressed instructions. This decoding step is particularly important since it determines if an instruction occupies 16 or 32 bits, which also determines when the next instruction starts. Super-scalar implementations needs to do that on large bit vectors within a few logic levels to ensure proper instruction throughput through decode and smaller implementation needs to do that efficiently to avoid wasting power decoding the wrong size of instruction.
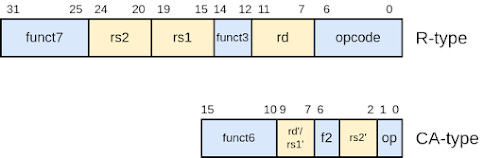
The base extension has a 7-bit opcode stored in the 7 least significant bits (visible in the R-type encoding) of the figure above. The compressed version uses a 2-bit opcode field stored in the 2 least significant bits. For all base extensions (including the V extension), the 2 least significant bits (out of 7) always take the value 0x3, while it can takes values 0x0, 0x1 or 0x2 for compressed instructions. Thus only 2 bits are required to discriminate between compressed and uncompressed instructions and to determine how many bytes (2 or 4) must be considered to get the complete instruction half-word/word.
Compatibility
Instructions of the Zcmp and Zcmt extensions reuse encodings of compressed double precision floating-point loads and stores and are thus incompatible with these instructions. This is in line with the philosophy of those new extensions: improve code size for embedded platforms where floating-point instructions are less critical (and may not even be implemented in their uncompressed formats).
Conclusion
Code size is a key metric for ISA performance and can greatly impact overall program performance.
In addition to the base C extension, the Zc* family of extensions provide a way to greatly improve code size for embedded applications by compressing whole program sequences into single instruction, including function start sequences and return sequences, ABI register moves and table jumps. The code size reduction task group has demonstrated substantial savings, their methods and result can be consulted on https://github.com/riscv/riscv-code-size-reduction. These extensions are mostly targeted at embedded systems.
References:
Tariq Kurd (spec editor) youtube video presentation on Zc* during RISC-V Europe Summit 2023
github repository for RISC-V code size reduction task group: https://github.com/riscv/riscv-code-size-reduction
Zc* specification V1.0.0-RC5.7 (pdf)
Wikipedia's page on Branch/Jump table https://en.wikipedia.org/wiki/Branch_table