
RISC-V Vector Is Expanding
An illustrated look at some of the on-going fast track extension projects for RVV

A little under a year ago (assuming we do not take too long to write this piece) we published a taxonomy of the ratified and some future RISC-V Vector extensions.
Taxonomy of RISC-V Vector Extensions

RISC-V Vector 1.0 (RVV) was ratified in November 2021. The main extension, dubbed simply the “v” extension (as in the letter V, not the roman numeral V), covers a lot of ground, with supported element sizes ranging from 8 to 64-bit and offering a plethora of formats (integer, floating-point, fixed-point, boolean mask, …) and countless operations. The R…
There has been a lot of recent activities in this domain and it is time to update its status. So let’s review a few of the on-going fast track vector extension projects.
Note: In RISC-V parlance, a fast track is project of extension(s) that is designed outside of the standard task group process. It is dimmed small enough to require less group discussions and it is expected to follow a lighter weight specification process (which is often much faster than the standard process). However it still goes through a lot of the same review steps (internal, architecture review committee, public review) as a non fast-track specification. The main difference is that the specification is built without the formation of a dedicated task group.
Sum of absolute difference: Zvabd
This project of extension introduces 5 new instructions: vabs.v, vabd.vv, vabdu.vv, vwabda.vv, vabdau.vv.
vabs.v: integer absolute valuevabd[u].vv: absolute difference [unsigned]vwabda[u].vv: accumulation of widened absolute difference [unsigned]
The specification is being developed in a separate repo, riscv/integer-vector-absolute-difference, and a draft pdf (v0.7) is already available.
vabs.v is specified for all valid element width (SEW) values (from 8 to ELEN), while vabd[u].vv and vwabda[u].vv are only specified for 8 and 16-bit elements. The argument being that since the main use is for digital signal processing, wider element sizes may not be very useful and could waste hardware resources if implemented (I don’t believe that saving some encoding spaces by reserving SEW values would be a driver for such decision).
The internal review started on January 19th 2026 (announcement) and the specification progress can be tracked on RVIA Jira space: RVS-3896 "Integer Vector Absolute Difference (Zvabd)".
Pairing / Unpairing: Zvzip
The Zvzip project of extension introduces 5 new instructions to manipulate pairs of data: vzip.vv, vunzip[e,o].vv, and vpair[e,o].vv.
All instructions can be optionally masked. The draft specification is available as a Pull Request against riscv-isa-manual (#2529). The process can be tracked on RVS-4161 "Vector Unzip Instruction (Zvzip)". Internal review discussion can be consulted here.
The following figures illustrates the behavior of each new instruction:
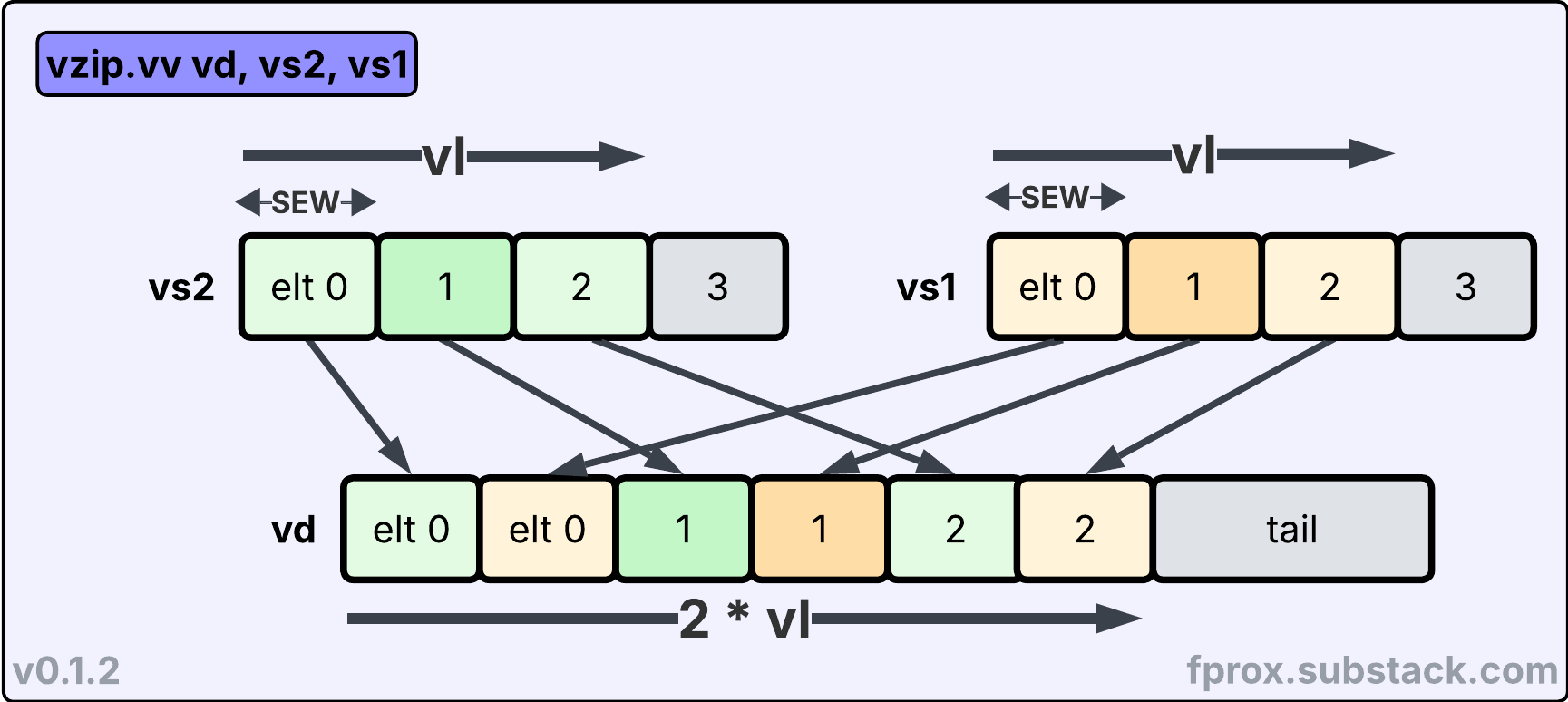
First vzip.vv which combines two input vector register group by interleaving their elements. The operation operates with an effective vector length equals to 2*vl, and the destination vd EMUL is 2*LMUL.
Then, the reciprocals: vunzipe.vv and vunzipo.vv, which extract the even (respectively odd) elements of a vector and group then into the destination vector register group. Mirroring vzip.vv, vunzip[e,o] can access up to 2*vl elements from its source, and the source vs2 EMUL is 2*LMUL
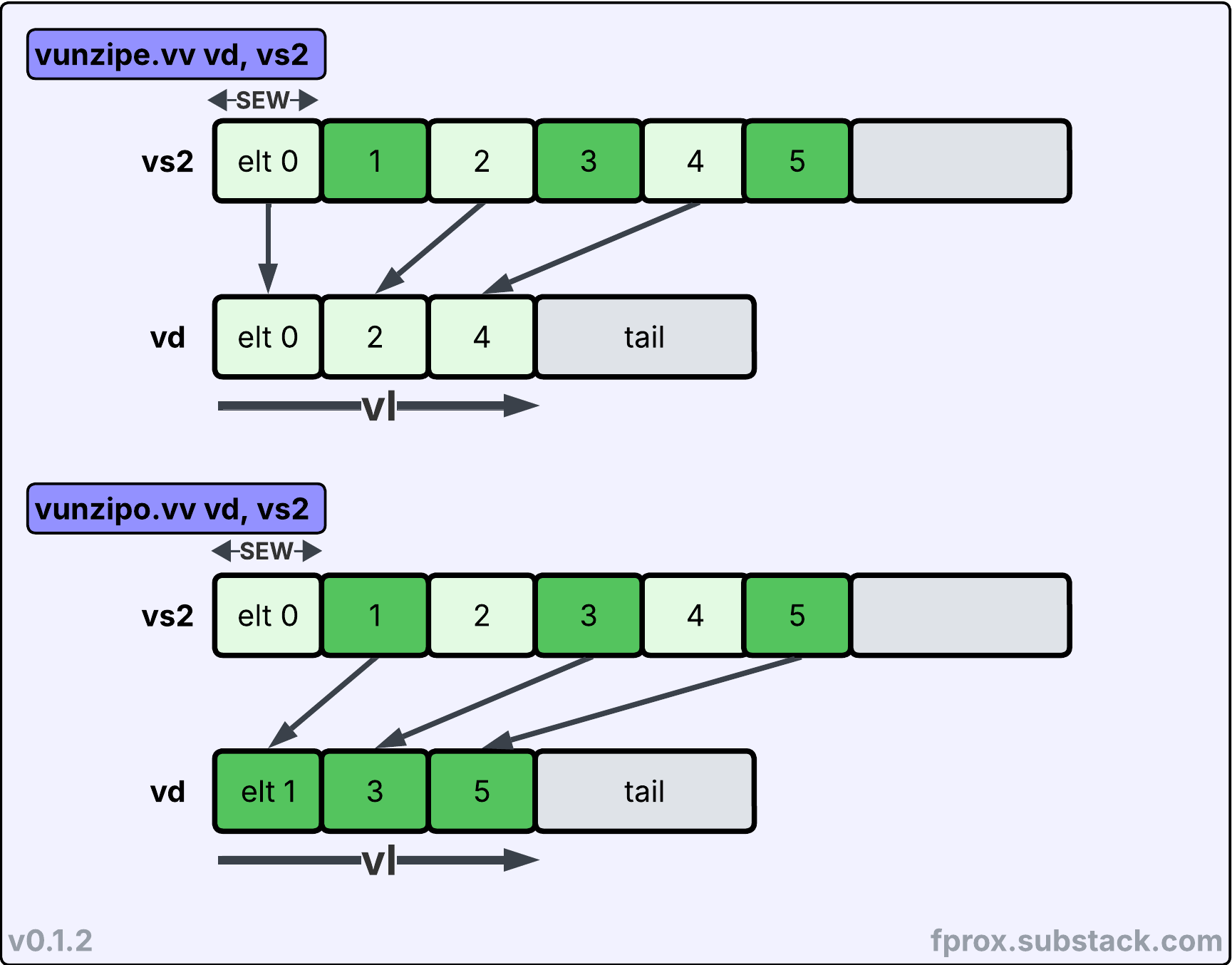
Note:
vunzip[e,o].vvcan be emulated with RVV 1.0vcompress.vminstruction with a few differences: the latter requires materializing two compression mask values, while the extraction/compression layout is implicit invunzip[e,o].vv. Furthermore,vunzip[e,o].vvcan be optionally masked whilevcompress.vmis always unmasked.
The last two instructions in Zvzip are vpair[e,o].vv which combine even (respectively odd) elements from two input vector register groups and interleave them.
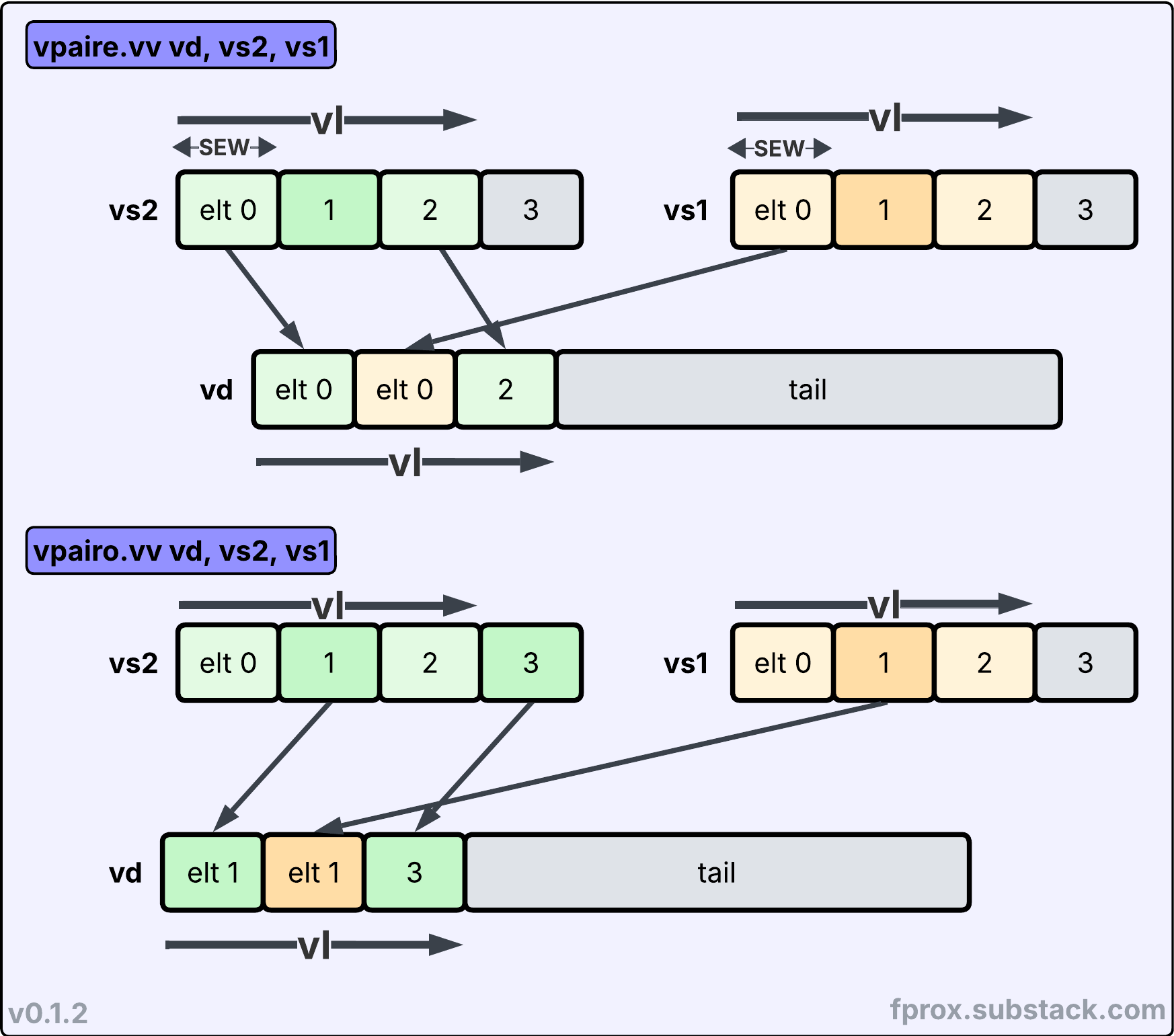
Note:
vpairo.vvhas a corner case, whenvlis odd, it is possible that the instruction reads an element beyond theVLMAXmask limit of thevs2vector register group. In that case, the specification mandates that the element is replaced by the value 0.
Vector 8-bit Dot Product: Zvdot4a8i
The Zvdot4a8i (previously called Zvqdotq) extension project specifies a small set of 4D dot products of 8-bit integers. The progress of the extension can be tracked here: RVS-1971 "Dot-Product (Zvqdot/Zvdot4a8i)".
This extension should be ratified ahead of any matrix extension (IME, VME, AME) that RVIA is currently working on.
Zvdot4a8i specifies 7 new instructions:
3 vector-vector instructions,
vdot4a.vv(signed-signed),vdot4au.vv(unsigned-unsigned), and,vdot4asu.vv(signed-unsigned)4 vector-scalar instructions:
vdot4a.vx,vdot4au.vx, and,vdot4asu.vx,vdot4aus.vx(unsigned-signed).
Note: there is no
vdot4aus.vvbecause it can easily be obtained by swappingvs2andvs1operands invdot4asu.vvand so was not worth the encoding.
The instructions operates independently on 32-bit elements. For vs2, vs1/rs1 a 32-bit element is a 4-element vector of 8-bit values. They are multiplied component wise and then accumulated together and finally accumulated with the corresponding 32-bit element from vd as illustrated by the figures below:
The difference between the vector-vector and the vector-scalar variants is that the vector-scalar variants broadcast a single 4-element vector of 8-bit values for independent dot product across all the 32-bit bundles from vs2 and vd as illustrated below:
Conclusion
RVV 1.0 is a large extension but it could not cover every needs. As it gets broader adoption, some opportunities for improvements have appeared. We reviewed some extra vector extensions already ratified in this Vector after RVV 1.0 (e.g. Zvfh(min) adding support for half-precision floating-point or vector crypto). We also covered other extension projects: Zvfofp8min (support for OCP’s OFP8 format)and Zvfbfa (extended vector support for BFloat16).
The on-going RVIA vector fast track projects described in this post, Zvabd, Zvzip, Zvdot4a8i, constitute the next waves of such improvements, requiring fewer discussions, they should be ratified more rapidly and will allow the next generation of RVV processors to provide better performance on some uses cases.
As usual you can get involved. A lot of the discussions occur either on the pull-request / repo of each extension project or on the RISC-V Vector Special Interest Group (vector sig mailing list).
References:
RVIA tracker for Zvabd: RVS-3896 “Integer Vector Absolute Difference (Zvabd)”.
RVIA tracker for Zvzip: RVS-4161 “Vector Unzip Instruction (Zvzip)”
opcodes: https://github.com/riscv/riscv-opcodes/pull/391/files
ISA manual: https://github.com/riscv/riscv-isa-manual/pull/2529
SAIL model: https://github.com/riscv/sail-riscv/pull/1449/files
arch-test: https://github.com/riscv-non-isa/riscv-arch-test/pull/804/files
riscv-config: https://github.com/riscv-software-src/riscv-config/pull/205
RVIA tracker for Zvdot4a8i: RVS-1971 “Dot-Product (Zvqdot/Zvdot4a8i)”
original spec repo: https://github.com/riscv/riscv-dot-product
ISA manual: https://github.com/riscv/riscv-isa-manual/pull/2576
SAIL model: https://github.com/riscv/sail-riscv/pull/1495
Spike simulator: https://github.com/riscv-software-src/riscv-isa-sim/pull/2212
vzip.vv could previously be done with `vwmaccu.vx(vwaddu.vv(a, b), -1U, b)`, vunzip[e,o].vv is vnsrl.vi and vpaire/vpairo are masked vslide1up/vslide1down.