
Adding a new RISC-V instruction (to spike)
Prototyping AES128 all-rounds encryption in spike simulator

In this post we are going to describe a possible method to extend one the main RISC-V ISA simulator (spike) to implement a single instruction inspired by a future extension: vector all-rounds NIST cryptography, a.k.a Zvknf (currently in draft mode). The selected instruction is the vector AES-128 all-rounds encryption. We will first describe this instruction before reviewing how to declare the new opcode in riscv-opcodes and how to describe and integrate the behavior of the new instructions in riscv-isa-sim.
What is all-rounds AES-128 encryption ?
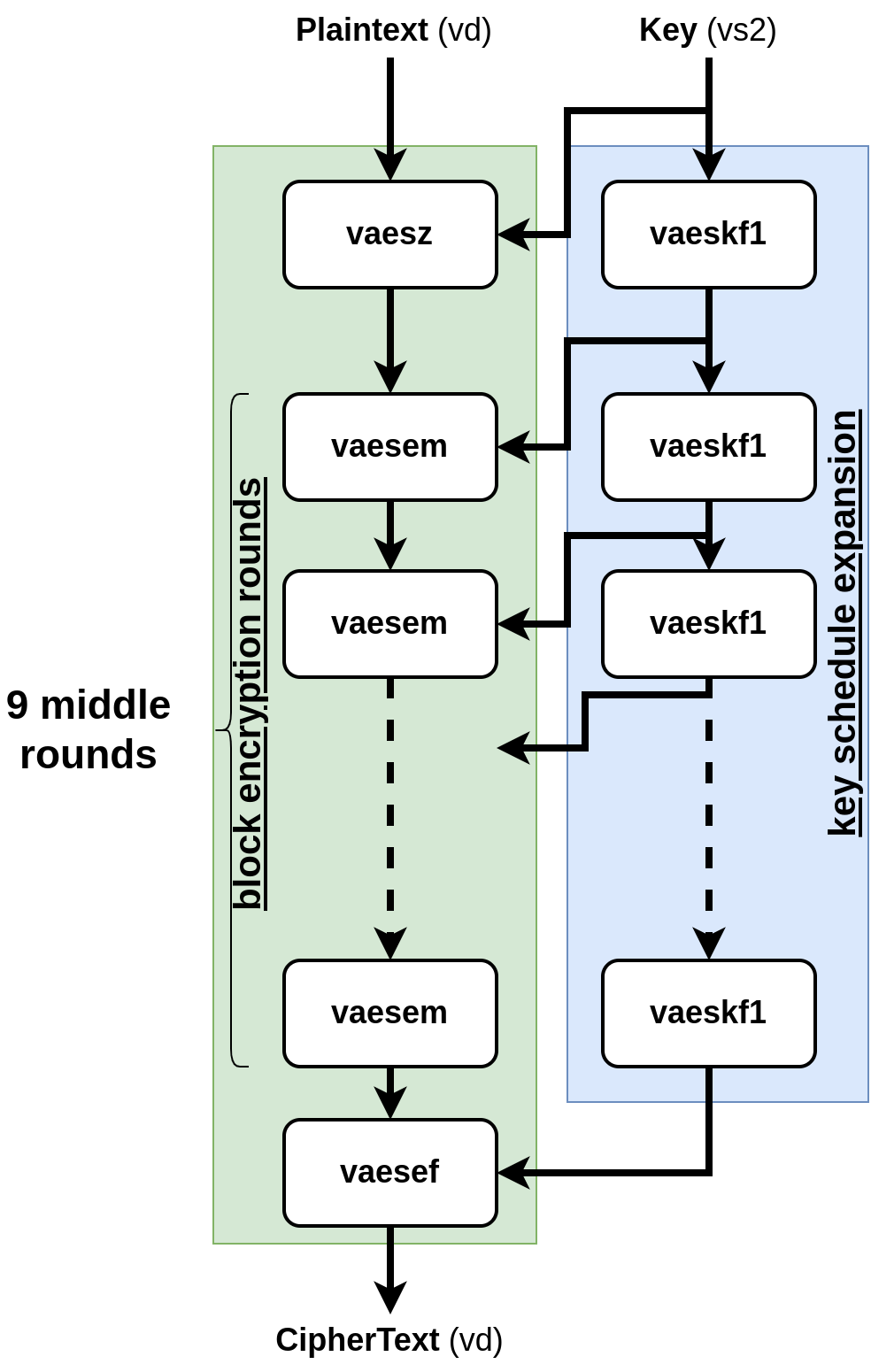
The selected instruction is a modified version of the vector all-rounds AES-128 encryption instruction: vaese128.vv vd, vs2. The specification of the original version, a.k.a vaese128.vv vd, vs2, vs1 (specification). Our version is modified compared to the original because we define it as destructive: vd is used both as an input for the plaintext block and as an output for the ciphertext. This allow us to remove the vs1 source operand (now merged with vd) to fit more easily in the opcode space. We keep the same element group parameter as the original (and as the single-round vaes instructions from Zvkned).
This instruction encrypts each 128-bit element group of the source vd using the corresponding 128-bit key element group in vs2, the resulting ciphertext is stored back into vd. The instruction performs the full expansion of the key schedule in parallel with the encryption and replaces 21 instructions from Zvkned.
As a basis we are going to use Rivos’ prototype of spike for the vector crypto extensions: https://github.com/rivosinc/riscv-isa-sim/tree/zvk-vector-crypto. This fork already supports the standard vector crypto extensions and it is easier to extend it with one all-round instructions.
Development environment
Eventually we need to build the following:
a new version of RISC-V opcode header files including the new instruction
an instruction simulator (spike) patched with:
support for the new extension
Zvknfsupport for our new instruction and a few collaterals required to build and execute a minimal test program.
We will also rely on a RISC-V compiler (which much supports the standard vector extension) and a RISC-V proxy kernel for simulation.
Adding opcodes
RISCV’s opcodes are managed in the riscv-opcodes project (https://github.com/riscv/riscv-opcodes.git). This is where any new opcode must be declared. Building the project will generate useful artefacts for downstream project and in particular header files with constants used by the simulator spike to decode/match instructions.
For our purpose, we need to modify riscv-opcodes by adding a new file in the unratified/ (the directory for unratified extensions):
riscv-opcodes/unratified/rv_zvknf
The new file should contain the following:
# AES-128 All Rounds Encryption
vaese128.vv 31..26=0x28 25=1 vs2 19..15=0x8 14..12=0x2 vd 6..0=0x77
vaese128.vs 31..26=0x29 25=1 vs2 19..15=0x8 14..12=0x2 vd 6..0=0x77(The change can be found in this commit on riscv-opcodes repository. On top of vaese128.vv, it contains vaese128.vs whose implementation is not covered in this post)
vaese128.vv encoding
The opc field (bits 6 down to 6) takes the value 0x77. It is the encoding of the OP-P opcode space used by most of the vector crypto instructions (except bit manipulation and carry-less multiply instructions). The funct3 field (bits 14 down to 12) takes the value 0x2, corresponding to OPMVV.
The function is encoded by the fields funct6 (bits 31 downto 16) and the field usually used to encoded rs1/vs1 source index (bits 19 downto 15). Our instruction is part of the VAES_VV encoding defined by a specific funct6 value (0x29) in the OP-P opcode space (opc=0x77). We use the rs1 field to encode the sub-function within the VAES_VV space using the value 0x8 which was previously unused.
Building riscv-opcodes artefacts
After installing python dependencies, let’s build from the top of riscv-opcodes directory by simply running make (after patching the repo):
$ make
Running with args : ['./parse.py', '-c', '-go', '-chisel', '-sverilog', '-rust', '-latex', '-spinalhdl', 'rv*', 'unratified/rv*']
Extensions selected : ['rv*', 'unratified/rv*']
INFO:: encoding.out.h generated successfully
INFO:: inst.chisel generated successfully
INFO:: inst.spinalhdl generated successfully
INFO:: inst.sverilog generated successfully
INFO:: inst.rs generated successfully
INFO:: inst.go generated successfully
INFO:: instr-table.tex generated successfully
INFO:: priv-instr-table.tex generated successfullyThis will generate multiple files. You can check the presence of the new instructions by looking at match and mask values in encoding.out.h, it should look something like:
(...)
#define MATCH_VAESE128_VS 0xa6042077
#define MASK_VAESE128_VS 0xfe0ff07f
#define MATCH_VAESE128_VV 0xa2042077
#define MASK_VAESE128_VV 0xfe0ff07f
(...)Extending RISC-V ISA Simulator
Declaring the new extension
As we add an instruction in a new (previously undeclared) extension we need to extend spike such that it can recognize the new extension, in particular in the ISA string which configures which extensions should be enabled in a simulation.
The addition of the Zvknf extensions can be found in this commit: patch ISA parser.
Adding instruction decoding
We are going to copy the relevant part of encoding.out.h generated during riscv-opcodes build into riscv-isa-sim/encoding.h: patch encoding import.
Adding instruction behaviour
The instruction behavior is implemented in a new source file:
riscv-isa-sim/riscv/insns/vaese128_vv.h
To simplify the task we are re-using a lot of the macros defined in zvkned_ext_macros.h and zvk_ext_macros.h and we have added a few new ones: patch with new macros. Those macros handle the glue code to check ISA and vconfig requirements and to unroll the behavior to be executed on all active element groups.
The implementation for the new instruction can be found in this commit: patch vaese128.v implementation. The structure of the behavior implementation is presented below:
VI_ZVK_VD_VS2_NOOPERANDS_PRELOOP_EGU32x4_NOVM_LOOP(
{
(...)
},
{}, // No PRELOOP.
{
(...)
// operand extraction
EGU8x16_t aes_state = P.VU.elt_group<EGU8x16_t>(vd_num, idx_eg);
EGU32x4_t round_key = P.VU.elt_group<EGU32x4_t>(vs2_num, idx_eg);
(...)
// first round (equivalent to vaez)
EGU8x16_XOREQ_EGU32x4(aes_state, round_key);
int roundId;
// middle round round 1 .. 10
for (roundId = 1; roundId < 10; roundId++) {
// expanding key (vaeskf1)
(...)
// actual middle round (vaesm)
(...)
}
// last key expansion (vaeskf1)
(...)
// final round (vaesf)
(...)
// Update the destination register.
EGU8x16_COPY(vd, aes_state);
}
);Once patched, you can follow the standard method to build spike:
$ apt-get install device-tree-compiler
$ mkdir build
$ cd build
$ ../configure --prefix=$RISCV
$ makeTest program
We build a minimal unit test program for our new instruction. The test uses data and known answer from section “C.1 AES-128 (Nk=4, Nr=10)” of the NIST AES specification (https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197.pdf).
We rely on the .insn assembly macro to embed our new instruction by directly describing the full opcode (RISC-V formats for this macro are documented here).
".insn r 0x77, 0x2, 0x51, x17, x8, x23\n"We use the R opcode format, which is the base 2-operand, 1-destination format. Although we have a single operand, there does not seem to be a format for the case where this unique operand is rs2.
The first field is the 7-bit opcode,
0x77(OP-P) in our caseThe second field is the 3-bit func3,
0x0(OPMVV) in our caseThe third field is the 7-bit func7 (func6 + unmasked),
0x51in our caseThe 4th field is
vd, mapped tov17in our case (encoded asx17)The 5th field is
vs1, which is0b01000and part of the opcode in our case (encoded asx8)The 6th and last field is
vs2, mapped tov8in our case (encoded asx8)
We assume we are going to execute on an implementation with VLEN >= 128, and so using LMUL=1 (m1) is sufficient to fit the AES key/cipher/plaintext 4x32-bit element groups.
Note: for smaller VLEN values, this LMUL would need to be extended, for example using
m2for VLEN=64
Here is the listing of the full test program (vaese128-test.c):
#include <stdio.h>
// Inputs and known answer taken from Section C.1
// of https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197.pdf
const char plaintext[16] = { 0x0, 0x11, 0x22, 0x33, 0x44, 0x55,
0x66, 0x77, 0x88, 0x99, 0xaa, 0xbb,
0xcc, 0xdd, 0xee, 0xff};
const char key[16] = {0x0, 0x1, 0x2, 0x3, 0x4, 0x5, 0x6,
0x7, 0x8, 0x9, 0xa, 0xb, 0xc, 0xd,
0xe, 0xf};
const char expected[16] = {0x69, 0xc4, 0xe0, 0xd8, 0x6a, 0x7b,
0x04, 0x30, 0xd8, 0xcd, 0xb7, 0x80,
0x70, 0xb4, 0xc5, 0x5a};
char ciphertext[16] = {0};
/** AES-128 encryption of a single 128-bit block
*
* @param dst address of destination buffer (must be at least 16-byte wide)
* @param src address of source buffer (must be at least 16-byte wide)
* @param key address of key buffer (must be at least 16-byte wide)
*
* The noinline attribute is not required and is just used to ensure
* the function will be visible as such in the generated assembly code.
*/
void __attribute__((noinline))
encrypt(char* dst, const char* src, const char* key) {
__asm__ volatile (
"vsetivli x0, 4, e32, m1, ta, ma\n" // setting vl=4
"vle32.v v17, (%[src])\n" // loading plaintext
"vle32.v v23, (%[key])\n" // loading key
// vaese128.vv using ".insn" R type macro:
// .insn r opcode, func3, func7, rd, rs1, rs2
".insn r 0x77, 0x2, 0x51, x17, x8, x23\n"
"vse32.v v17, (%[dst])\n" // storing ciphertext
:
: [src]"r"(src), [key]"r"(key), [dst]"r"(dst)
:
);
}
#define PRINT_EGU8x16(LABEL, X) do {\
printf("%s: %02x %02x %02x %02x" " %02x %02x %02x %02x" \
" %02x %02x %02x %02x" " %02x %02x %02x %02x\n",\
(LABEL),\
(X)[0], (X)[1], (X)[2], (X)[3], (X)[4], (X)[5], \
(X)[6], (X)[7], (X)[8], (X)[9], (X)[10], (X)[11], \
(X)[12], (X)[13], (X)[14], (X)[15]);\
} while (0);
int main(void) {
encrypt(ciphertext, plaintext, key);
PRINT_EGU8x16("plaintext ", plaintext)
PRINT_EGU8x16("ciphertext", ciphertext)
PRINT_EGU8x16("expected ", expected)
return 0;
}Building out test program
riscv64-unknown-elf-gcc -O2 -march=rv64gcv -o test.bin vaese128-test.cHere we use a version of gcc built with vector support (any other compiler with RVV 1.0 can be used). Vector support is required since our instruction is working on vector registers and we need support to manipulate values in those registers. Since we are relying on the .insn macro to call our new instruction there is no need for the compiler nor for the assembler to support this new instruction.
Executing our test program
We are going to use our newly built instruction simulator to simulate our test program. A build of pk (the proxy-kernel) is also required, although this build has no dependency on our changes.
The test can be executed as follows (replacing <pk> by the actual path to your proxy kernel build):
$ ./spike --isa=rv64gcv_zvknf --varch=vlen:128,elen:64 <pk> test.bin
bbl loader
plaintext : 00 11 22 33 44 55 66 77 88 99 aa bb cc dd ee ff
ciphertext: 69 c4 e0 d8 6a 7b 04 30 d8 cd b7 80 70 b4 c5 5a
expected : 69 c4 e0 d8 6a 7b 04 30 d8 cd b7 80 70 b4 c5 5aAs expected (what a relief!) the instruction output matches the NIST known answer for this test: we have successfully implemented a single instruction to perform the full encryption of a 128-bit AES plaintext block (which works on at least one element group).
Conclusion
This minimal example illustrates that it is not very difficult to extend the RISC-V ISA (at least for functional simulation). Obviously this experiment is just that, an experiment, and a lot of work and testing is still required. Next steps could included: adding a .vs variant, adding support for decryption/key schedule instructions, adding AES-256 all-rounds instruction, adding support in the assembler and compiler (including intrinsics), adding Zvknf support to QEMU (an other simulator) and gem5 (yet another simulator with performance modeling capabilities).
At the time of writing, Rivos has open a PR against the official (upstream) riscv-isa-sim repository: https://github.com/riscv-software-src/riscv-isa-sim/pull/1303. We will update this post to apply on the upstream repository once the PR has been merged.
References
Spike implementation branch https://github.com/nibrunie/riscv-isa-sim/tree/zvknf-support
Full official specification (in draft stage) of the vector crypto all-rounds extension: https://github.com/riscv/riscv-crypto/tree/master/doc/vector-allrounds