
Accelerating CRC with RISC-V Vector
Zvbc(32e) for the win

In this post we describe a way to compute a cycle redundancy check (CRC) hash using RISC-V Vector extension (a.k.a. RVV). This application is well suited for being optimized with one of the recently ratified vector cryptographic extension, Zvbc, and we will also discuss what could be the benefit of an additional vector crypto extension under preparation: Zvbc32e (temporary name).
CRC in a nutshell
CRC stands for Cyclic Redundancy Check. It is a type of checksum based on computing a polynomial division remainder. There exists more than one form of CRC. A CRC specification defines a polynomial P with boolean coefficients (each coefficient is a bit with true/false, 0/1 value) of degree equal to the length of the CRC (e.g. degree 32 for a 32-bit checksum). The input message M, which can be of arbitrary length, is interpreted as a polynomial with boolean coefficients. This polynomial is divided by P (often after initial padding) and the remainder of the division is the checksum.
Note: there are numerous CRC specifications. They differ by the size of the polynomial/checksum but also by the order in which their interpret the bits and bytes of the input message (endianness).
Here is an example of 32-bit big endian CRC implemented in the Linux kernel (the full source code is available here (only the CRC_BE_BITS == 1 section has been reproduced with some ellipsis for conciseness):
/**
* crc32_be_generic() - Calculate bitwise big-endian Ethernet
* AUTODIN II CRC32
* @crc: seed value for computation. ~0 for Ethernet, sometimes 0 for
* other uses, or the previous crc32 value if computing
* incrementally.
* @p: pointer to buffer over which CRC32 is run
* @len: length of buffer @p
* @tab: big-endian Ethernet table
* @polynomial: CRC32 BE polynomial
*/
static u32 crc32_be_generic(u32 crc, unsigned char const *p,
size_t len, const u32 (*tab)[256],
u32 polynomial)
{
int i;
while (len--) {
crc ^= *p++ << 24;
for (i = 0; i < 8; i++)
crc = (crc << 1) ^ ((crc & 0x80000000) ? polynomial : 0);
}
return crc;
}This code reads each message byte from p and adds (xor-ing) the byte to the current CRC value (in the most significant byte position):
crc ^= *p++ << 24;Note: in the arithmetic used for CRCs (arithmetic on polynomial with boolean coefficients), an addition corresponds to a XOR (each bit is added independently).
The byte is added at the most significant byte position. And then modulo reduce each byte with the following loop:
for (i = 0; i < 8; i++)
crc = (crc << 1) ^ ((crc & 0x80000000) ? polynomial : 0);The modulo reduction is implemented by XOR-ing the CRC polynomial if the most significant bit of the current accumulator is set. This reduction assumes that the most significant bit is the highest degree coefficient of the corresponding polynomial and that the reducing polynomial is also laid out as most significant degree (31) in most significant bit position.
Note: for the modulo polynomial, the highest degree coefficient, corresponding to degree 32, needs not to be encoded as it is always 1 and will always cancel out with exiting bit in the shift
crc << 1. Those 32 bits are enough to store a degree 32 polynomial (with 33 boolean/bit coefficients)
Implementing the CRC this way is rather slow: each inner loop iteration reduces a single bit and requires a few operations (shift, XOR, parity comparison). It is easy to speed it up without any new instruction by using tables: for example pre-computing the 32-bit result of the modulo reduction of every possible byte value: there are 256 values to compute and the table only depends on the polynomial which is constant for a given CRC. So you trade off code size (embedding the table) for performance. The Linux kernel code exploits these techniques and the size of the table can be configured with the CRC_BE_BITS macro (the macro sets the width of the table index).
The following diagram illustrates how this implementation works:

Each one Byte Reduction step represents an iteration of the outer while loop where a byte is XOR-ed to the current CRC value and reduced.
Note: the source code for the Linux Kernel implementation of the little-endian version of the CRC can be found here.
Computing CRC with folding
A modulo reduction of a polynomial with boolean coefficients is a rare operation in most workloads but it can be quite common in some common workload (e.g. ethernet, Gzip, BZIP2, …).
ARM ISA implements a CRC32 instruction (optional in ARM v8-A, supported since ARM v8.1, targeting the CRC used in the ethernet protocol and variation compression libraries). On the x86 side, SSE 4.2 introduced a CRC32(C) instruction computed with the polynomial used for iSCSI (different from the ethernet one). Those instructions target specific CRCs and work on scalar operands.
Carry-less Multiplication
There exist a well known technique based on multiplication of polynomials with boolean coefficients to accelerate CRC computation using carry-less multiplication. This technique can also easily be parallelized to process multiple words of message at the same time.
Generic multiplications of polynomials with boolean coefficients can be used beyond CRC. This operation is often referred to as carry-less multiplication and can be used in various cryptographic primitives including the widespread Galois Counter Mode (e.g. in AES-GCM) which relies on a 128-bit x 128-bit carry-less multiplication followed by a modulo reduction to compute the authentication tag.
This multiplication is called carry-less because it can be seen as a multiplication of two integer numbers without any carry-propagation: the partial products are evaluated by AND-ing together operand bits but the compression of the partial product array is performed with XOR operations rather than addition (XOR is the addition in boolean algebra) and XORs dot not generate any carry.
CRC Folding
The well-known algorithm to compute CRC using carry-less multiplication, sometimes called “folding”, is simple and based on the fact that:
Here A.X^n is a chunk of the input message (it can be seen as a chunk of message A padded to the right with n zeroes assuming the first message byte is on the left).
With the formal definition of CRC (BE) being:
This transforms a CRC reduction of a long padded message into a carry-less multiplication.
Note that A.R is as wide as the sum of the width of A and R (minus 1).
A m-bit CRC can be evaluated by iterating on m-bit wide chunks of messages; lets consider A and B two such m-bit chunks and the message consisting of the concatenation of A and B (A appearing first in message order):
So if we consider the case of n=m, we get:
Chaining carry-less multiplications and XOR operations with new chunks of the message delaying the evaluation of the original CRC reduction to the last step (a single CRC operation on a very reduced message width is still required).

CRC folding in RVV with Zvbc
In late 2023, RVIA ratified a set of vector crypto extensions, including Zvbc.
We presented Zvbc in a previous post. It introduces two new instructions, vclmul and vclmulh, which can be combined to build a full 64-bit carry-less multiplication (with 127-bit result spread across two vector register groups, one for the high 63 bits, the other for the low 64 bits).
We are just going to describe the main loop of our implementation. The full source code for a somewhat optimized implementation of 32-bit CRC BE using Zvbc is available on src/crc/vector_crc_be.c#L95.
Note: This code was written with 128-bit VLEN in mind but could easily be extended to wider VLEN.
for (; avl >= 2*vl; avl -= vl, p += 8 * vl, len -= 8*vl) {
// compute loop body vector length from application
// vector length avl.
// the current implementation assumes VLEN=128-bit and
// may misbehave if actual vl is not 2
assert(vl == 2);
vuint64m1_t inputData = __riscv_vle64_v_u64m1((uint64_t*) p, vl);
// byte swapping the data to align their endianess
// with the CRC accumulator
inputData = __riscv_vrev8_v_u64m1(inputData, vl);
inputData = __riscv_vxor_vv_u64m1_tu(inputData,
inputData,
crcAcc, 2);
// Actual multiplication
// Note: since the constant multiplicands are 32-bit wide,
// the upper 32-bit of vclmulh results are always 0
vuint64m1_t multResLo = __riscv_vclmul_vv_u64m1(inputData,
extRedCstVector,
vl);
vuint64m1_t multResHi = __riscv_vclmulh_vv_u64m1(inputData,
extRedCstVector,
vl);
crcAccLo = __riscv_vredxor_vs_u64m1_u64m1(multResLo,
zeroVecU64M1,
vl);
crcAccHi = __riscv_vredxor_vs_u64m1_u64m1(multResHi,
zeroVecU64M1,
vl);
crcAcc = __riscv_vslideup_vx_u64m1(crcAccHi, crcAccLo, 1, 2);
}This code starts by loading a new chunk of data in inputData and then byte reversing every 64-bit double word. The latter action is required because in CRC the first bytes of the message correspond to the highest degrees of the corresponding polynomial. The byte reversed chunk is XOR-ed with the current value of the CRC accumulator. Then the accumulator is multiplied by the folding reduction constants. The multiplication results are reduced and concatenated to form the new accumulator value.
The CRC accumulator in this implementation is 96-bit wide. This width results from the multiplication of 64-bit wide data chunks by the 32-bit folding constants.
This underutilizes the carry-less multiplication provided by Zvbc’s vclmul and vclmulh instructions which are both 64-bit multiplier with 64-bit results (in practice vclmulh’s result is only 63-bit wide but is still stored in 64-bit wide elements).
RVV implementation with Zvbc32e
The official RISC-V Zvbc ISA extension only specifies a single element width for vector carry-less multiplication: 64-bit elements. This forbids implementation on vector CPU supporting at most 32-bit elements (ELEN=32, Zve32) and also implies some inefficiencies and underutilization when it comes to using vector carry-less multiplication to implement CRC folding as we have seen previously.
Introducing Zvbc32e
Zvbc32e is a project of new extension for RISC-V vector, it is still in draft state (it has not been publicly reviewed, ratified nor approved). It extends the validity of two instructions introduced in Zvbc: vclmul.[vv,vx] and vclmulh.[vv,vx]. In Zvbc, those two instructions were defined only for SEW=64 (64-bit element) and were reserved for all other SEW value. Zvbc32e extends this definition to SEW=32 (and possibly to 8 and 16-bit as well).
Note: Effort to specify Zvbc32e is tracked in this PR against riscv-isa-manual.
Implementation using Zvbc32e
The full source code of the “somewhat optimized” vector BE 32-bit using Zvbc32e is available here. We have reproduced the inline assembly code listing for the inner loop.
asm volatile (
"mv a2, %[bound]\n"
"bgeu %[p], a2, 2f\n" // skipping inner loop for short len
"vmv.v.i v11, 0\n"
"vsetivli zero,4,e32,m1,tu,ma\n"
"1:\n"
"vle32.v v13, (%[p])\n"
"vrev8.v v13, v13\n"
"vxor.vv v13, v13, %[crcAcc]\n"
"vclmul.vv v20, v13, %[redConstantVector]\n"
"vclmulh.vv v13, v13, %[redConstantVector]\n"
"vredxor.vs v11, v20, v8\n"
"vredxor.vs %[crcAcc], v13, v8\n"
"vslideup.vi %[crcAcc], v11, 1\n"
"add %[p], %[p], 16\n"
"bltu %[p], a2, 1b\n"
"2:\n"
: [p]"+r"(p), [len]"+r"(len),
[avl]"+r"(avl), [crcAcc]"+vr"(crcAcc),
[redConstantVector]"+vr"(redConstantVector)
: [bound]"r"(p + len - 16)
: "v10", "v13", "v20", "v12", "v8", "v11", "a2"
);This code is very similar to an optimized version of the code with Zvbc. The big difference is that the code based on Zvbc32e operates on 4 32-bit elements from the input message rather than 2 64-bit element for the code based on Zvbc. The code throughput (instruction per 128-bit block) is very similar (with identical optimization effort).
The Zvbc based implementation was done using RVV intrinsics (rather than assembly for the Zvbc32e based one) and it gets compiled into a 14-instruction loop body versus 10 for the assembly version. The two differences that explain this count discrepancy are:
The assembly version with Zvbc32e uses a single variable/register to store the source address and do the comparison for end-of-loop exits (pre-computing the final pointer and comparing against it and using this pre-computed final pointer in the loop epilog). This saves 2 instructions.
The assembly version does not use any
vset*instruction in the loop body. This also saves two instructions. The intrinsics version needs to insertvset*instruction because of the XOR intrinsics forcing the tail-undisturbed mode (when xor-ing the current CRC accumulator in the new message chunk). This can be removed by forcing all vector instructions in the loop body to operate under the tail undisturbed policy (even if this is not actually required).
The visible difference is at the micro-architectural level: the code based on Zvbc32e fully exploits four 32-bit carry-less multipliers while the code based on Zvbc exploits only half of two 64-bit carry-less multipliers.
Experimentations
All the source code used in this post is available on github: rvv-examples/src/crc.
As far as I am aware there is no RISC-V hardware readily available with support for the vector crypto extensions (in particular Zvbc). So we will have to rely on simulator and generic metrics to compare our implementations. I have selected the number of retired instructions.
Note (usual disclaimer): The number of retired instructions is often a poor metric to approximate real performance (on real hardware). It does not take into account the micro-architecture of the particular implementation were the benchmark is being run (latency of an operation in the pipeline, bottleneck in various structure such as instruction queues, register file access ports, memory hierarchy such as caches, queues …).
In particular for vector, it is easy to reduce the number of retired instructions by increasing the group multiplier (LMUL). Although this will often help the CPU front-end being more efficient (less instructions to fetch) it often has less impact on the backend: most implementations have sized their vector datapath to execute a VLEN wide instructions and will have to sequence operations which manipulate vector register group with LMUL > 1 into multiple micro operations.
All implementations considered here are using LMUL=1.
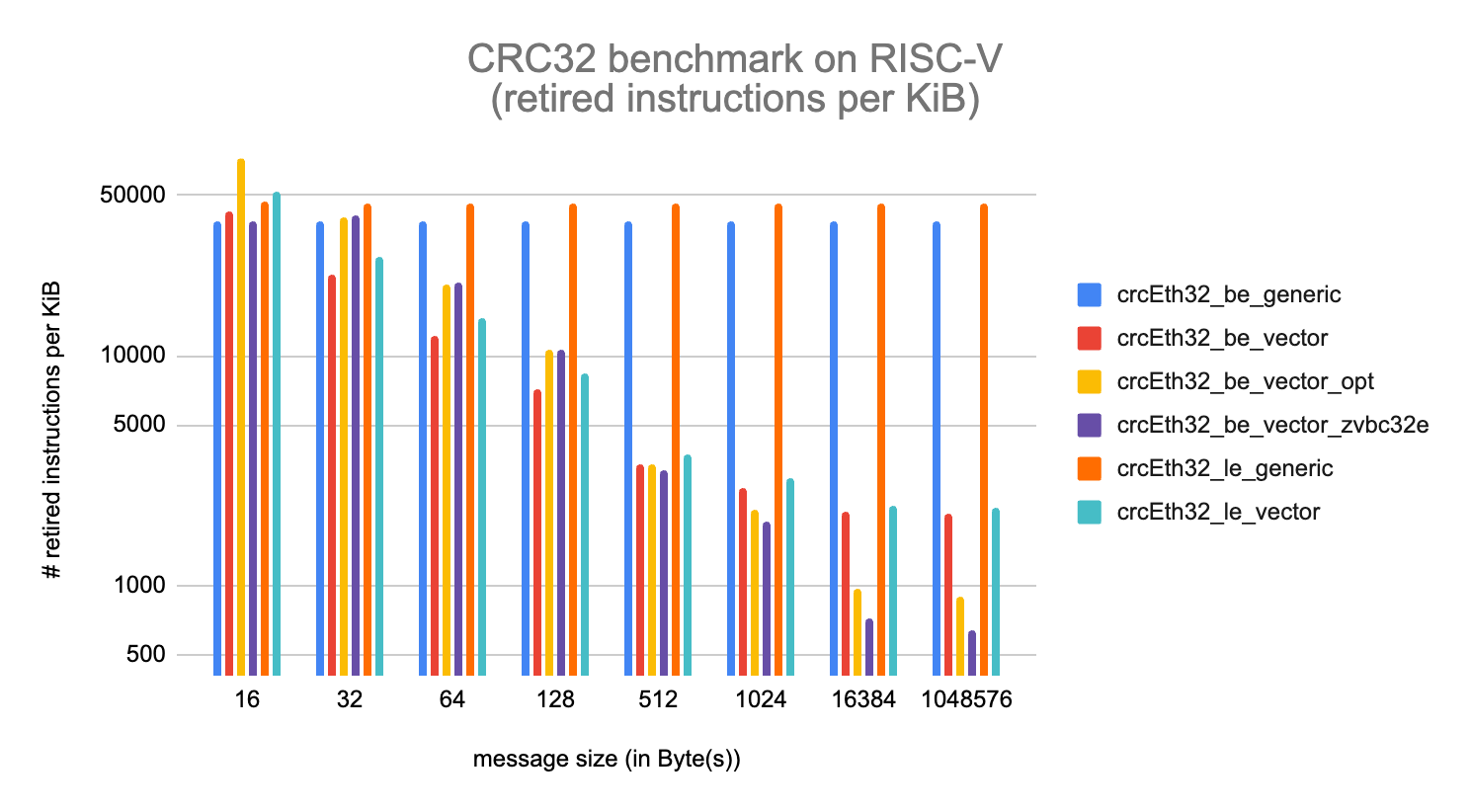
The benchmark results are presented below. The trend shows an amortized cost when the message size grows. The generic version exhibits a terminal rate of about 39 cycles per Byte for the BE version and 46 cycles per Byte for the LE version. Those terminal rates do not vary much with the message size (the rate are very similar whether the message is 16-Byte long or 1 MiB long).
The Zvbc32e implementation (crcEth32_be_vector_zvbc32e) shows the best result with a terminal rate of about 0.641 cycle per Byte. The Zvbc based optimization, crcEth32_be_vector, would certainly exhibit a similar rate if it was optimized with the same effort. Assuming a sufficiently wide message, the vector implementation relying on Zvbc(32e) exhibits much higher throughput than the generic versions.
Conclusion
In this post we have presented the Cyclic Redundancy Check (a.k.a. CRC) and how it is built on arithmetic over polynomials with boolean coefficients. We have illustrated how RISC-V Vector Cryptography Zvbc extension can be leveraged to implement high throughput CRC using the well-known “folding” technique. This technique can be leveraged to get more than one byte per cycle throughput with a VLEN=128-bit implementation. We have also introduced Zvbc32e, a variant of Zvbc, currently under specification, and leveraged it to implement an optimized assembly version of CRC. We have demonstrated an implementation with a theoretical throughput of 1.56 Bytes per cycle (assuming a theoretical implementation which can execute one instruction per cycle, with 1-cycle latency over all instructions).
Even the most optimized version in this post has a lot of room for improvement. The use of a reduction operation (often slow in most RVV implementation) should be avoided. This could be done by independently reducing each 32-bit element in a new vector by a different reduction factor and eventually combining the reduction in the loop epilog. A larger LMUL could also be used (with an expanded reduction constant), improvement the ratio of operations per fetched instructions. A vector load with negative stride could be used to perform both the load and the byte reversal operation. The order of reduction constants will need to be modified in this case. However, this would need to be evaluated on a real hardware as the actual efficiency of such strided load might be low.
Reference(s)
Intel white paper: Intel(R) Carry-Less Multiplication Instruction and its Usage for Computing the GCM Mode about using their carry-less multiply instruction to compute GCM using the folding technique
RISC-V ISA Manual Vector Cryptography chapter, section on Zvbc (source code sampled Sept 2nd 2024)
RISC-V ISA Manual Pull Request #1306 tracking Zvbc32e (and Zvkgs) specification
ARM documentation on ARM v8.1 CRC32 instruction
Independent documentation of x86 CRC instruction
Very nice job, well done.